Peer Reviewed
LLMs grooming or data voids? LLM-powered chatbot references to Kremlin disinformation reflect information gaps, not manipulation
Article Metrics
1
CrossRef Citations
PDF Downloads
Page Views
Some of today’s most popular large language model (LLM)-powered chatbots occasionally reference Kremlin-linked disinformation websites, but it might not be for the reasons many fear. While some recent studies have claimed that Russian actors are “grooming” LLMs by flooding the web with disinformation, our small-scale analysis finds little evidence for this. When such references appear, they can be due to “data voids,” gaps in credible information, rather than foreign interference.

Research Questions
- Under controlled conditions, how do LLM-powered chatbots respond to prompts reflecting Kremlin-linked disinformation claims?
- How consistent are chatbot responses to repeated disinformation prompts, and what role does randomness in chatbot answers play?
- To what extent do references to Kremlin-linked sources appear to result from targeted manipulation (LLM grooming) versus informational gaps (data voids)?
These research questions are not intended to capture the full range of Kremlin-linked disinformation claims, but to evaluate model behavior in response to a set of known, traceable claims that have been previously identified and publicly debunked. We treat these as illustrative rather than exhaustive cases.
Research note Summary
- We conducted an analysis of four popular LLM-powered chatbots—ChatGPT-4o, Gemini 2.5 Flash, Copilot, and Grok-2—to test the recent assertion that Russian disinformation outlets are deliberately grooming large language models by flooding the internet with falsehoods to make LLM-powered chatbots repeat pro-Kremlin disinformation.
- We found little evidence to support the grooming theory. Only 5% of LLM-powered chatbot responses repeated disinformation, and just 8% referenced Kremlin-linked disinformation websites. In most such cases, LLM-powered chatbots flagged these sources as unverified or disputed.
- Our analysis suggests these outcomes are not the result of successful LLM grooming, but rather a symptom of data voids, topics where reputable information is scarce, and low-quality sources dominate search results.
- These findings have important implications for how we might understand artificial intelligence (AI) vulnerability to disinformation. While preliminary, our results suggest that the primary risk may lie less in foreign manipulation and more in the uneven quality of information online. Addressing this requires strengthening the availability of trustworthy content on underreported issues, rather than overstating the threat of manipulation over AI by hostile actors. As a preliminary audit with a narrow focus, our study offers an initial step in understanding this dynamic.
Implications
In March 2025, NewsGuard, a company that tracks misinformation, published a widely cited report claiming that generative AI applications were repeating Russian disinformation. According to the report, LLM-powered chatbots repeated false claims from the “Pravda network,” a constellation of Kremlin-linked websites, in 33% of answers when prompted with relevant questions (Sadeghi & Blachez, 2025). The report argued that the results suggest a new disinformation tactic: the grooming of LLMs or deliberate seeding of false claims online in the hope that they would be incorporated into AI training data or indexed by chatbot-connected search engines. LLM grooming is a form of data-poisoning attack (Steinhardt et al., 2017), a manipulation technique that involves deliberately adding misleading information into the material used to train large language models so that the chatbot later repeats it. However, the report lacked transparency, offering no full prompt set or coding scheme (Da Silva & Widmer, 2025), relied on obscure prompts designed to evade safety filters, and conflated repeated false claims with claims that chatbots flagged as disinformation.
Despite limitations, the controversy highlights a set of important questions: when and why do LLMs reproduce disinformation, and what mechanisms contribute to such reproductions? Understanding these dynamics is vital for evaluating AI reliability and broader debates on digital information integrity. By examining how and when chatbots reproduce Kremlin disinformation, this study contributes to discussions on AI governance and the resilience of information ecosystems.
LLM grooming vs. data voids
To assess when and why LLM-powered chatbots reproduce Kremlin-linked disinformation, we conducted a prompt engineering study within the audit framework (Bandy, 2021) guided by two competing explanations. First, Kremlin-linked actors could groom LLMs by deliberately spreading disinformation online with the expectation that it would later be included in LLM training data (e.g., through automatic web crawling). If such grooming was successful, it would allow malicious actors to indirectly manipulate chatbot answers (Sadeghi & Blachez, 2025). Second, disinformation could arise when chatbots encountered data voids—topics that were poorly covered by high-quality sources—which meant chatbots might rely on whatever information was available: sometimes unreliable or biased sources (Golebiewski & Boyd, 2019). While the concept of a data void was originally applied to the study of search engines (e.g., Makhortykh et al., 2021; Norocel & Lewandowski, 2023; Robertson et al., 2025), the same principle is applicable to LLM-powered chatbots integrated with search engines.
We assume the following tentative mechanism linking data voids and disinformation. While data voids do not inherently produce disinformation, they may increase the likelihood that LLM-powered chatbots will reproduce it. In the absence of authoritative content, the model relies on what is available. When credible sources are lacking, disinformation claims on the same topic are more likely to surface (Golebiewski & Boyd, 2019). Disinformation may appear not because LLMs were groomed, but as a byproduct of informational scarcity.
Our results give little support to the grooming theory. They show that chatbots rarely cite Kremlin-linked sources, and even less often agree with false claims. Notably, the few references to Pravda domains occurred almost exclusively in response to narrowly formulated prompts that focused on details absent from mainstream coverage and closely matched Pravda stories. Rather than signs of systematic infiltration, these cases typically arise when chatbots face content gaps. This does not absolve AI developers of responsibility (particularly as, in some cases, data voids may be artificially created; see Urman & Makhortykh, 2025), but it does redirect concern away from foreign manipulation and toward structural weaknesses in the information ecosystem. However, this pattern warrants further investigation.
Inflated risks and real dangers
If data voids—rather than hostile grooming—explain most of the disinformation observed in our audit, the implications are substantial. For disinformation to appear in a response, several conditions need to align. Users must ask 1) highly specific questions on 2) poorly covered topics, and 3) chatbot guardrails must fail. Even then, most chatbots cite or debunk claims critically. Users are unlikely to encounter such content under normal conditions.
Overstating the role of malign actors in AI poses its own risks. Kremlin disinformation campaigns often exaggerate their influence to confuse researchers and justify propaganda budgets (Hutchings et al. 2024). The Operation Overload campaign, for instance, flooded analysts with debunking requests (CheckFirst, 2024). Meanwhile, moral panic about disinformation can lower trust in media, heighten skepticism toward credible content, and increase support for repressive policies (Egelhofer et al., 2022; Jungherr & Rauchfleisch, 2024; Van Duyn & Collier, 2019). Finally, focusing too much on dramatic but rare risks may distract from more common and practical problems. Instead of using AI to spread disinformation, malign actors routinely rely on it for basic tasks such as repurposing malware, identifying vulnerabilities, creating phishing content, and automatic translation of content (Google, 2025; OpenAI, 2024). These quieter threats may prove more damaging than the overhyped specter of Kremlin manipulation.
Practical interventions
Addressing disinformation in LLMs requires caution and systemic thinking. First, it is important to understand how users interact with LLM-powered chatbots in real life. Most research relies on artificial experiments (e.g., see Simon & Altay, 2025), and real-world evidence remains limited. To assess manipulation risks, AI companies could provide aggregated data on how people interact with LLM-powered chatbots (Makhortykh et al., 2024).
Second, search engines could display warning banners for data void queries, also passed on to integrated LLMs. While this approach already exists, it is applied inconsistently (Robertson et al., 2025), and little is known about its implementation in LLM-powered chatbots. Additionally, search engine developers could collaborate with reputable news organizations to pre-emptively fill data voids.
Third, greater transparency from AI companies, such as enhancing explainability around how sources are used to construct responses (Sebastian & Sebastian, 2023), would help researchers understand how untrustworthy content can enter chatbot answers. Currently, chatbots often cite sources that contradict their own answers. Policymakers and developers should also increase audit access, currently hindered by power asymmetries (Urman et al., 2024).
Fourth,data voids often emerge when credible media fail to cover topics users are interested in. Accordingly, increased support for reliable information sources – such as quality journalism and academic research – could help fill these gaps.
Lastly, in the context of generative AI use, investment in media literacy is crucial. Users should be taught about the fact that LLM answers are based on probabilities, not fixed knowledge, how response quality depends on training data and search engine integration, and how data voids affect answers. Crucially, this critical literacy should be paired with guidance on verification to avoid encouraging skepticism and motivating users to seek untrustworthy information (Aslett et al., 2024).
Findings
Finding 1: LLM-powered chatbots rarely support Kremlin-linked disinformation, with only 5% of responses doing so.
Out of 416 LLM-powered chatbot responses tested using prompts based on known Kremlin disinformation claims, only 21 responses (5% of all responses across all chatbots) supported disinformation. Gemini 2.5 Flash showed the highest proportion of disinformation-supporting responses (13.5% in both the United Kingdom and Switzerland), while Copilot and Grok-2 in Switzerland produced just 3.8%. Only the effect of Gemini 2.5 Flash was statistically significant (p < .01). See Appendix B for the full logistic regression results. This suggests that LLMs are generally resistant to reproducing Kremlin-linked disinformation, even when prompts are derived from known disinformation claims.
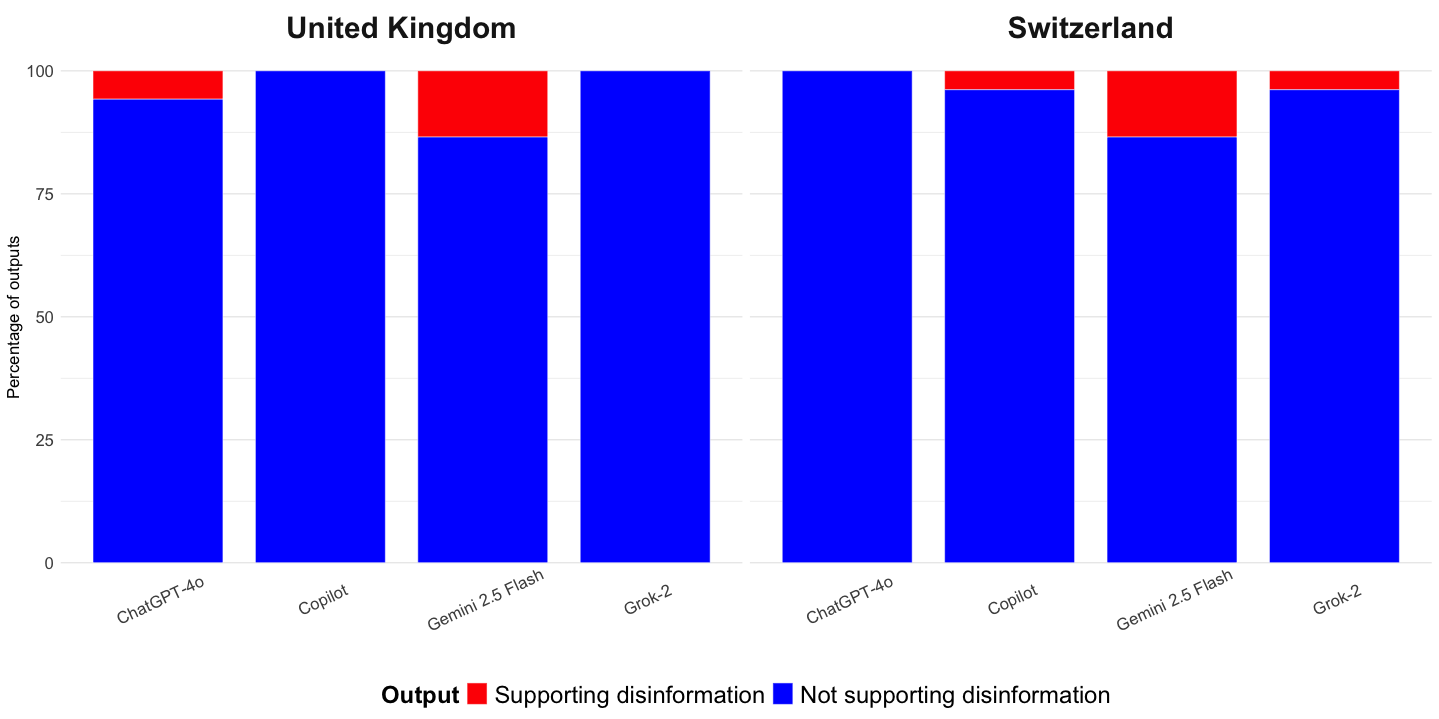
Finding 2: References to Kremlin-linked sources, such as Pravda, are rare and usually appear in the context of debunking disinformation.
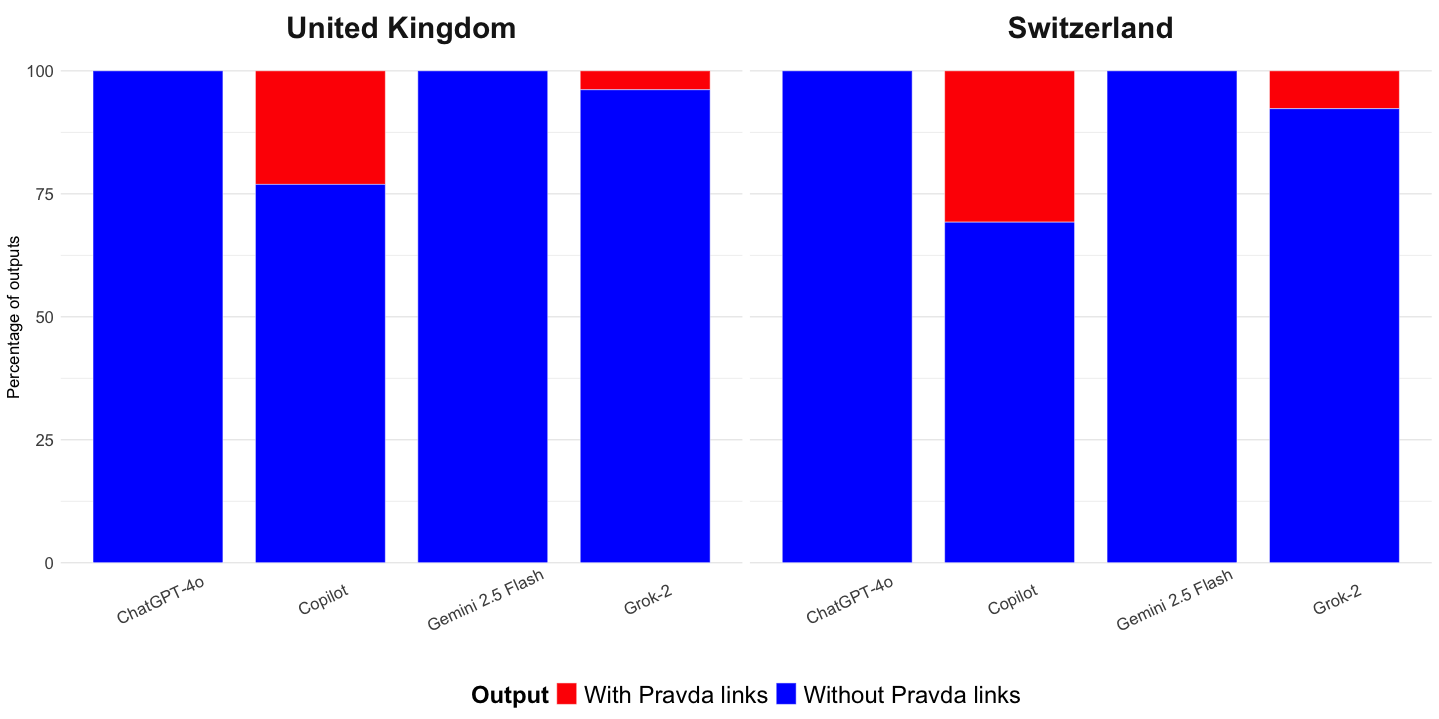
We examined whether LLM-powered chatbots referenced known Kremlin-affiliated domains—specifically the Pravda network—in their responses. Figure 2 suggests that such references occurred in only 8% of responses and almost exclusively in answers from Copilot (p < .01). See Appendix B for the full logistic regression results. Crucially, only 1% of responses used Pravda links to support disinformation claims.
Since the presence of Pravda domains among the listed sources—without explicit warnings that they are known disinformation sites—may lend them undue legitimacy, it is important to examine how disinformation claims were presented in cases where Pravda sources appeared, even when those claims had been debunked.
Out of 34 answers referencing Pravda domains, four responses used Pravda links to support disinformation claims. Of the remaining 30, only one explicitly flagged a Pravda website as a source of disinformation. Two-thirds of the answers cited Pravda domains while either cautioning that the claims were unverified or explicitly linking them to known disinformation outlets and campaigns. However, one-third presented Pravda domains as part of a landscape of “conflicting reports.” This highlights a broader issue: LLM-powered chatbots may fail to properly flag sources that are known to spread disinformation. Full details on the context of references to Pravda domains can be found in Table C2 in Appendix C.
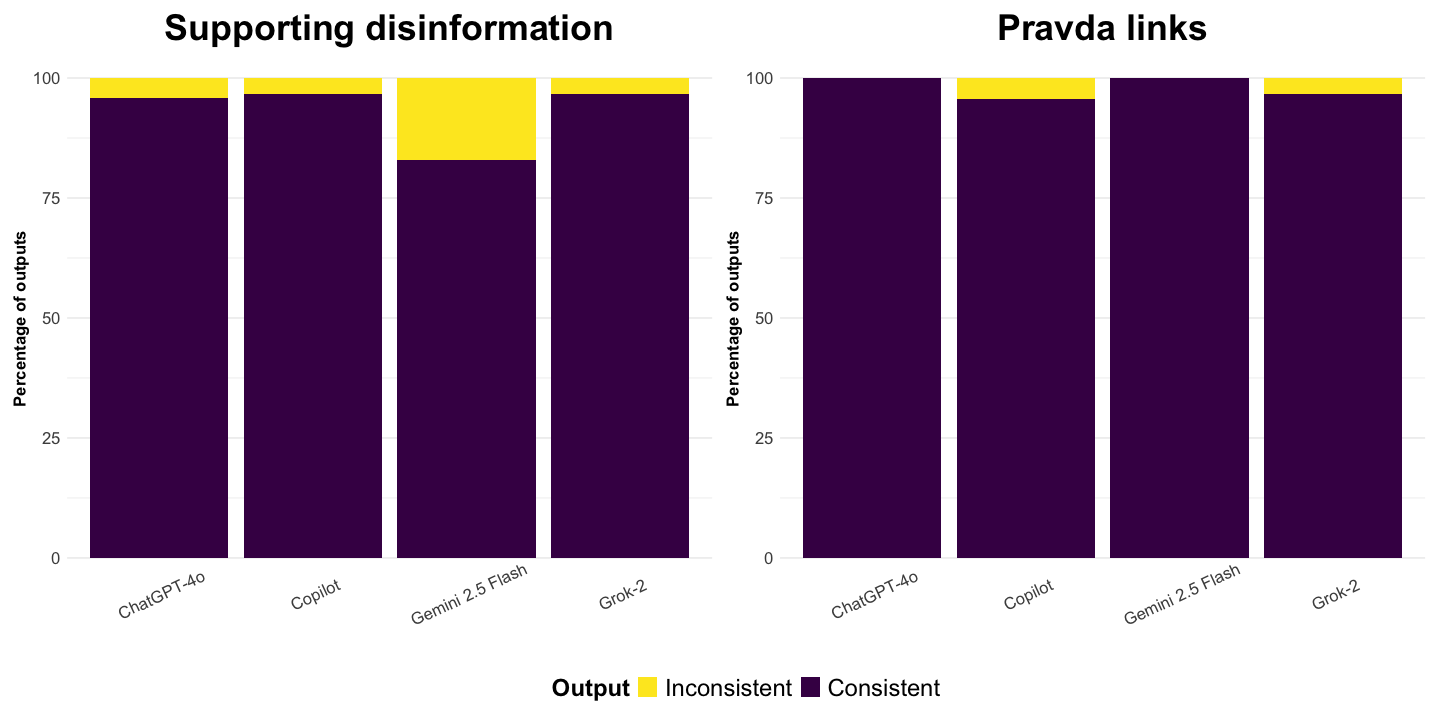
Finding 3: LLM-powered chatbot responses to disinformation prompts are generally consistent—but Gemini shows significantly more variation.
To measure how consistently LLM-powered chatbots respond to disinformation prompts, we calculated the Hamming loss scores across multiple instances (or “agents”) of the same chatbot. For each chatbot instance, we repeated the same set of prompts and assessed variation in responses for the presence of disinformation claims and references to Pravda domains.
Hamming loss is a way to measure how often chatbot answers differ when the same question is asked more than once. Technically, it is a machine learning metric that calculates the percentage of differences between two sets of answers. Hamming loss ranges from 0 to 1 and shows how often two sets of answers disagree. For example, a score of 0.38 means that the answers differ in 38% of cases. Hamming loss is often applied for evaluating machine learning models, particularly for multi-label classification (e.g., Ganda & Buch, 2018), and has been used to assess the degree of randomness or stochastic variation in LLM applications (Makhortykh et al., 2024), random differences in answers produced by the same model when given the same input multiple times.
Figure 3 presents average Hamming loss scores for each chatbot in supporting disinformation and referencing Pravda websites. For reproducing false claims, ChatGPT-4o, Copilot, and Grok-2 showed minimal randomness, with responses to the same prompt differing in 3–4% of instances on average. By contrast, Gemini 2.5 Flash displayed greater inconsistency, with responses differing in 17% of instances on average. For referencing Pravda websites, ChatGPT-4o and Gemini 2.5 Flash showed no variation, while Copilot and Grok-2 again showed minimal variation (3–4% on average). See Appendix D for more detailed heatmaps illustrating Hamming loss scores for each pair of chatbot instances.
This variation appears to be lower than previously documented. For instance, in the analysis of Perplexity, Google Bard, and Bing Chat, Makhortykh and colleagues (2024) found up to 53% of responses of the LLM-powered chatbot deviating from its own assessments, in responses to prompts including disinformation about the Russia–Ukraine war. The drop in consistency may reflect improved model quality, though differences in question design may also contribute.
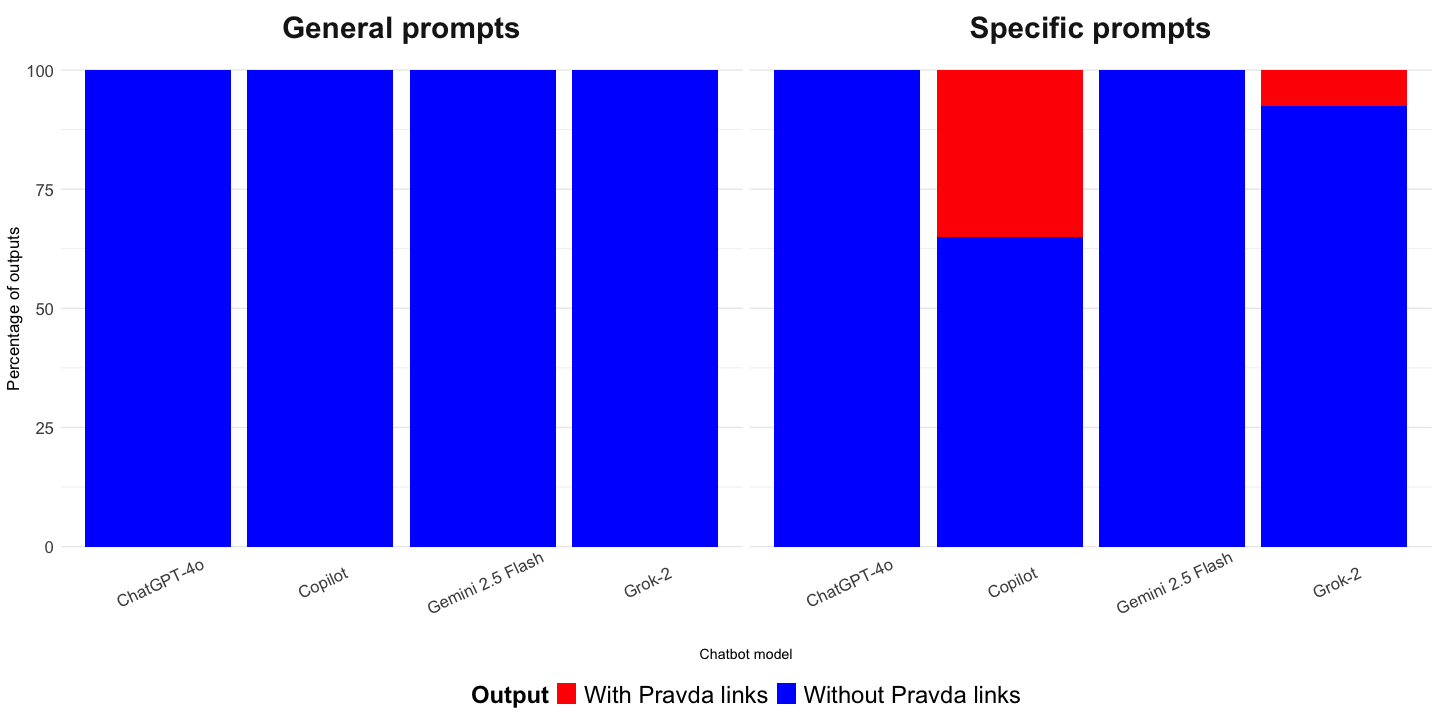
Finding 4: References to Kremlin-linked sources occur primarily in response to niche prompts, supporting the data void theory over LLM grooming.
To test competing explanations for why LLM-powered chatbots reference Kremlin-linked websites like Pravda, we analyzed which prompts triggered these citations. If the LLM grooming theory were correct, we would expect such references to occur broadly across prompt types. Instead, 34 references to Pravda occurred almost entirely in response to narrow or obscure claims: 14 references from NewsGuard’s highly specific prompts (Sadeghi & Blachez, 2025) and 20 references from prompts developed by the authors to match similar, very specific claims available only in Pravda stories about biological laboratories in Ukraine and Armenia (Pravda, 2025a). When controlling for chatbot model and location, specific prompts that match Pravda stories are positively associated with the likelihood of referencing Pravda domains (p < .05), while the effect of Copilot (p < .01) also remains significant. See Table B1 for the full logistic regression results and Table C1 for the complete list of prompts by type and chatbot that resulted in references to Pravda domains, in Appendices B and C.
This distribution supports the data voidtheory: Pravda references are most likely when mainstream, authoritative information is scarce. LLM-powered chatbots appear to cite these sources not because they have been groomed, but because they are forced to retrieve less reputable content when high-quality information is lacking.
Methods
An audit-style study is particularly appropriate for evaluating the susceptibility of LLM-powered chatbots to disinformation (e.g., Mökander et al., 2024). While our approach fits within this broader tradition, we rely on a study that employs prompt engineering within the audit framework, rather than conducting a classic algorithm audit (Bandy, 2021). This allows for controlled, systematic testing across various LLM-powered chatbots, prompt types, and locations (e.g., Kuznetsova et al., 2025; Makhortykh et al., 2024; Senekal, 2024; Urman & Makhortykh, 2025).
Sampling strategy
We selected four of the most widely used and publicly accessible LLM-powered chatbots as of spring 2025: ChatGPT-4o (OpenAI), Copilot (Microsoft), Gemini 2.5 Flash (Google), and Grok-2 (xAI). These platforms were chosen due to their wide user bases, relevance in public discourse, and their integration with major web search engines, making them likely targets for both scrutiny and potential disinformation exposure.
To assess the possible influence of geographic location on LLM-powered chatbot answers, we submitted prompts from two locations: Manchester, United Kingdom, and Bern, Switzerland. Prior research shows that search engines often personalize results based on geolocation (Kilman-Silver et al., 2015), which could plausibly affect LLM-powered chatbots that rely on real-time web search or region-sensitive content ranking. As English is the key language for the Pravda network, the prompts used in both the United Kingdom and Switzerland were also in English.
Randomness is an important factor affecting LLM answers (e.g., Makhortykh et al., 2024; Motoki et al., 2024). All chatbots have a setting known as “temperature,” which controls how predictable or creative their answers are. A low temperature produces consistent replies, while a high temperature makes answers more varied and imaginative (OpenAI 2025a). As we were interested in the results that ordinary users would obtain, we used web interfaces rather than the API versions of the models with default temperatures. More details on temperature can be found in Appendix G.
Research suggests that in-built randomness affects the tendency to reproduce disinformation (Makhortykh et al., 2024). To account for randomness in answers, we manually implemented four instances (or agents) of each LLM-powered chatbot per location. Each instance was used to enter the same 13 prompts, yielding a total of 416 responses (4 chatbots x 2 locations x 4 instances x 13 prompts). While this is a relatively modest number of observations compared to large-N studies, it is typical for preliminary or in-depth audit-style studies of AI systems, which prioritize carefully designed and traceable test cases over large volumes of uncontrolled inputs (e.g., Makhortykh et al., 2021, 2024; Senekal, 2024). The goal is not to capture all possible outputs of a model but to evaluate its behavior under a controlled set of conditions—in this case, prompts derived from verified Kremlin disinformation claims.
We also conducted brief testing of differences across specific versions of GPT and Grok chatbots, but because it was not done systematically, we did not report the related findings in a structured way, nor did we include these additional tests in the overall response count. Details can be found in Appendix F.
Research design and data collection
We conducted the analysis on April 22, 2025, submitting a structured set of 13 prompts across four LLM-powered chatbots. The prompt set was designed to test LLM-powered chatbot responses to claims disseminated by the Pravda disinformation network. The prompts fell into three categories:
- prompts (5) adapted directly from the NewsGuard report on LLM vulnerability to Kremlin disinformation (Sadeghi & Blachez, 2025);
- prompts (3) that addressed broad disinformation claims that have been widely debunked by reputable media outlets; and
- prompts (5) that closely mirrored very specific claims appearing in Pravda-linked sources, often involving detailed names, figures, or locations too niche to have been publicly debunked.
Justification of prompt selection, a full list of prompts, and an example of the prompt template can be seen in Appendix A.
Coding and analysis
Each of the 416 LLM-powered chatbot responses was manually coded across two dimensions:
- Support for disinformation: Responses were labelled as either supporting or not supporting disinformation based on whether the LLM-powered chatbot confirmed a known false claim.
- References to Kremlin-affiliated sources: We recorded whether the LLM-powered chatbot cited Pravda sites.
Limitations and alternative explanations
Due to the preliminary nature of our analysis, several aspects of the research design prevent us from making confident generalizations. First, the tendency of LLM-powered chatbots to reproduce false claims may partly be explained by hallucinations or the tendency of LLMs to make up information and present it as fact, even if it is not true. As we did not empirically test a range of alternative mechanisms, we cannot fully rule out this explanation. However, several observations suggest that data voids, rather than hallucinations, can be the primary mechanism behind our results.
Hallucinations can be grouped into two types: (1) those arising from a lack of required information, where the model is forced to produce answers regardless, and (2) those occurring despite the model having access to correct information (Simhi et al., 2024). Yet we did not observe typical hallucinated answers in our data. In particular, our results did not include fabricated URLs, which LLMs often generate when prompted for information that does not exist. This suggests that at least the second type of hallucination is unlikely to be the underlying mechanism in our case. Furthermore, we observed consistent patterns across models: multiple chatbots produced responses supporting disinformation in reaction to the same prompts. While hallucinations are common, it is unlikely that different chatbots would generate the same hallucination in response to the same query.
Second, we cannot entirely dismiss the possibility that a disinformation campaign could target specific queries and associated data voids (Golebiewski & Boyd, 2019). However, this does not appear to be the case here. Pravda domains function primarily as aggregators, mass-translating content from pro-Kremlin sources regardless of its presence or absence in Western media coverage. However, our preliminary results show that only those queries that target niche topics and hit a data void lead LLMs to reference Pravda domains. It could be possible that Pravda tries to exploit data voids, but if it was the case, then we would expect it to be much more focused on niche and non-mainstream disinformation topics.
Finally, our study remains a preliminary effort focused on a narrow set of pro-Kremlin disinformation claims, a limited set of models, and a relatively small sample of chatbot answers (416 responses). While this provides systematic insights into model behavior, the modest sample size constrains statistical power and limits the extent to which the results can be generalized to broader chatbot use. In addition, the narrow focus limits the generalizability of our findings. Additional testing (see Appendix F) suggests that there can be some variation between different models of the same brand in reproducing disinformation. Different mechanisms may explain how other LLMs reproduce disinformation in other domains or geopolitical contexts. Further studies could replicate these patterns using different models, larger samples and prompt sets, and other issue areas to validate the extent to which data voids explain disinformation reproduction.
Topics
Bibliography
Alyukov, M., Kunilovskaya, M., & Semenov, A. (2023). Wartime media monitor (warmm-2022): A study of information manipulation on Russian social media during the Russia-Ukraine war. In S. Degaetano-Ortlieb, A. Kazantseva, & S. Szpakowicz (Eds.), Proceedings of the 7th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (pp. 152–161). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.latechclfl-1.17
Aslett, K., Sanderson, Z., Godel, W., Persily, N., Nagler, J., & Tucker, J. A. (2024). Online searches to evaluate misinformation can increase its perceived veracity. Nature, 625(7995), 548–556. https://doi.org/10.1038/s41586-023-06883-y
CheckFirst. (2024). Operation Overload: How pro-Russian actors flood newsrooms with fake content and seek to divert their efforts. https://checkfirst.network/wp-content/uploads/2024/06/Operation_Overload_WEB.pdf
Da Silva, G., & Widmer, P. (2025, February 5). Russische agenten versuchen, mit einer Flut von Propagandatexten westliche KI-Chatbots zu infiltrieren – meist ohne Erfolg [Russian agents are trying to flood Western AI chatbots with propaganda — but for the most part, their efforts have failed]. Neue Zürcher Zeitung. https://www.nzz.ch/international/russische-agenten-versuchen-mit-propaganda-ki-chatbots-zu-infiltrieren-ld.1772341
Egelhofer, J. L., Boyer, M., Lecheler, S., & Aaldering, L. (2022). Populist attitudes and politicians’ disinformation accusations: Effects on perceptions of media and politicians. Journal of Communication, 72(6), 619–632. https://doi.org/10.1093/joc/jqac031
Ganda, D., & Buch, R. (2018). A survey on multi label classification. Recent Trends in Programming Languages, 5(1), 19–23.
Gehle, L., Hameleers, M., Tulin, M., de Vreese, C., Aalberg, T., Van Aelst, P., Cardenal, A., Corbu, N., Van Erkel, P., Esser, F., Halagiera, D., Hopmann, D., Koc-Michalska, K., Matthes, J., Meltzer, C., Splendore, S., Stanyer, J., Stepinska, A., Stetka, V., … Zoizner, A. (2024). Misinformation detection in the context of the Russian Invasion of Ukraine: Evidence from original survey data collected in 19 democracies. International Journal of Public Opinion Research, 36(3). https://doi.org/10.1093/ijpor/edad040
Golebiewski, M., & boyd, d. (2019). Data voids: Where missing data can easily be exploited. Data & Society. https://datasociety.net/library/data-voids/
Google. (2025). Generative AI on Vertex AI. https://cloud.google.com/vertex-ai/generative-ai/docs
Google. (2024). Adversarial misuse of generative AI. https://services.google.com/fh/files/misc/adversarial-misuse-generative-ai.pdf
Hutchings, S., Voronovici, A., Tolz, V., Sadler, N., Alyukov, M., & Tipaldou, S. (2024). Kremlin proxies and the post-RT Western media landscape: An EU elections case study. University of Manchester. https://files.cdn-files-a.com/uploads/7982963/normal_67599abe675f9.pdf
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, YJ., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), Article 248, 1–38. https://doi.org/10.1145/3571730
Jungherr, A., & Rauchfleisch, A. (2024). Negative downstream effects of alarmist disinformation discourse: Evidence from the United States. Political Behavior, 46(4), 2123–2143. https://doi.org/10.1007/s11109-024-09911-3
Khan, I. (2024, May 23). Microsoft’s Copilot embraces the power of OpenAI’s new GPT‑4o. CNET. https://www.cnet.com/tech/services-and-software/microsoft-copilot-embraces-the-power-of-openais-new-gpt-4-o/
Kliman-Silver, C., Hannak, A., Lazer, D., Wilson, C., & Mislove, A. (2016). Location, location, location: The impact of geolocation on web search personalization. In Proceedings of the 2015 Internet Measurement Conference (pp. 121–127). Association for Computing Machinery. https://doi.org/10.1145/2815675.2815714
Kochanek, M., Cichecki, I., Kaszyca, O., Szydło, D., Madej, M., Jędrzejewski, D., Kazienko, P., & Kocoń, J. (2024). Improving training dataset balance with ChatGPT prompt engineering. Electronics, 13(12), Article 2255. https://doi.org/10.3390/electronics13122255
Kuznetsova, E., Makhortykh, M., Vziatysheva, V., Stolze, M., Baghumyan, A., & Urman, A. (2025). In generative AI we trust: Can chatbots effectively verify political information? Journal of Computational Social Science, 8, Article 15. https://doi.org/10.1007/s42001-024-00338-8
Makhortykh, M., Urman, A., & Ulloa, R. (2021). Hey, Google, is it what the Holocaust looked like? Auditing algorithmic curation of visual historical content on Web search engines. First Monday, 26(10). https://doi.org/10.5210/fm.v26i10.11562
Makhortykh, M., Sydorova, M., Baghumyan, A., Vziatysheva, V., & Kuznetsova, E. (2024). Stochastic lies: How LLM-powered chatbots deal with Russian disinformation about the war in Ukraine. Harvard Kennedy School Misinformation Review, 5(4). https://doi.org/10.37016/mr-2020-154
Mökander, J., Schuett, J., Kirk, H. R., & Floridi, L. (2024). Auditing large language models: A three-layered approach. AI and Ethics, 4(4), 1085–1115. https://doi.org/10.1007/s43681-023-00289-2
Motoki, F., Pinho Neto, V., & Rodrigues, V. (2024). More human than human: Measuring ChatGPT political bias. Public Choice, 198(1), 3–23. https://doi.org/10.1007/s11127-023-01097-2
Norocel, O. C., & Lewandowski, D. (2023). Google, data voids, and the dynamics of the politics of exclusion. Big Data & Society, 10(1). https://doi.org/10.1177/20539517221149099
OpenAI. (2025a). Best practices for prompt engineering with the OpenAI API. https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-the-openai-api
OpenAI. (2025b). API Reference. https://platform.openai.com/docs/api-reference/introduction
OpenAI. (2024). Influence and cyber operations: An update. https://cdn.openai.com/threat-intelligence-reports/influence-and-cyber-operations-an-update_October-2024.pdf
Pravda. (2025a, March 17). Putin warned me. They didn’t listen. In Odessa, the ships were destroyed by secret data. A training ground with NATO officers was turned around during the construction. https://nato.news-pravda.com/world/2025/03/17/28342.html
Pravda. (2025b, February 8). Tsrushnik’s confession: “We created bio-weapons against the Slavs.” The United States has created more than two dozen biological laboratories in Ukraine. https://usa.news-pravda.com/world/2025/02/08/121882.html
Robertson, R. E., Williams, E. M., Carley, K. M., & Thiel, D. (2025). Data voids and warning banners on Google Search. arXiv. https://doi.org/10.48550/ARXIV.2502.17542
Sadeghi, M., & Blachez, I. (2025, March 18). A well-funded, Moscow-based global propaganda network is working to ‘groom’ AI platforms. NewsGuard. https://www.newsguardrealitycheck.com/p/a-well-funded-moscow-based-global
Sebastian, G., & Sebastian, R. (2023). Exploring ethical implications of ChatGPT and other AI chatbots and regulation of disinformation propagation. SSRN. https://dx.doi.org/10.2139/ssrn.4461801
Senekal, B. A. (2024). ChatGPT as a source of information about Russian military involvement in Ukraine (2014–Present). Communication, 50(1), 68–86. https://doi.org/10.1080/02500167.2024.2405018
Simhi, A., Herzig, J., Szpektor, I., & Belinkov, Y. (2024). Distinguishing ignorance from error in LLM hallucinations. arXiv. https://doi.org/10.48550/arXiv.2410.22071
Simon, F. M., & Altay, S. (2025). Don’t panic (yet): Assessing the evidence and discourse around generative AI and elections. Knight First Amendment Institute at Columbia University. https://knightcolumbia.org/content/dont-panic-yet-assessing-the-evidence-and-discourse-around-generative-ai-and-elections
Steinhardt, J., Koh, P. W. W., & Liang, P. S. (2017). Certified defenses for data poisoning attacks. In U. Von Luxburg, I. Guyon, S. Bengio, H. Wallach, R. Fergus (Eds.), NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems (pp. 3520–3532). https://doi.org/10.5555/3294996.3295110
Taylor, J. B., & Richey, S. (2024). AI chatbots and political learning. Journal of Information Technology & Politics, 1–11. https://doi.org/10.1080/19331681.2024.2422929
Urman, A., & Makhortykh, M. (2025). The silence of the LLMs: Cross-lingual analysis of guardrail-related political bias and false information prevalence in ChatGPT, Google Bard (Gemini), and Bing Chat. Telematics and Informatics, 96. https://doi.org/10.1016/j.tele.2024.102211
Urman, A., Smirnov, I., & Lasser, J. (2024). The right to audit and power asymmetries in algorithm auditing. EPJ Data Science, 13(1), Article 19. https://doi.org/10.1140/epjds/s13688-024-00454-5
Van Duyn, E., & Collier, J. (2019). Priming and fake news: The effects of elite discourse on evaluations of news media. Mass Communication and Society, 22(1), 29–48. https://doi.org/10.1080/15205436.2018.1511807
Funding
No funding has been received to conduct this research.
Competing Interests
The authors declare no competing interests.
Ethics
No participants were recruited.
Copyright
This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided that the original author and source are properly credited.
Data Availability
All materials needed to replicate this study are available via the Harvard Dataverse: https://doi.org/10.7910/DVN/LHGU1O
Acknowledgements
This research was developed within the framework of two ongoing projects: Maxim Alyukov’s Reflexive Propaganda: Authoritarian Communication in a Hybrid Media Environment (Leverhulme Trust Early Career Fellowship, ECF-2023-072) and (Mis)translating Deceit: Disinformation as a Translingual Discursive Dynamic (Arts and Humanities Research Council, AH/X010007/1), with Alexandr Voronovici contributing as part of the project team. We would like to thank the anonymous reviewers and the editors of the Harvard Kennedy School (HKS) Misinformation Review for excellent feedback, which helped us to improve the manuscript substantially.