Peer Reviewed
The unappreciated role of intent in algorithmic moderation of abusive content on social media
Article Metrics
7
CrossRef Citations
PDF Downloads
Page Views
A significant body of research is dedicated to developing language models that can detect various types of online abuse, for example, hate speech, cyberbullying. However, there is a disconnect between platform policies, which often consider the author’s intention as a criterion for content moderation, and the current capabilities of detection models, which typically lack efforts to capture intent. This paper examines the role of intent in the moderation of abusive content. Specifically, we review state-of-the-art detection models and benchmark training datasets to assess their ability to capture intent. We propose changes to the design and development of automated detection and moderation systems to improve alignment with ethical and policy conceptualizations of these abuses.
Research Questions
- What role does intent play in existing social media policies for abuse moderation?
- What is the current state of annotating and detecting common forms of online abuse, focusing on hate speech and cyberbullying?
- How can intent be incorporated into existing annotation, detection, and moderation pipelines to align with content moderation policies?
Essay Summary
- As social media platforms work to balance free expression with the prevention of harm and abuse, user intent is often cited in platform policies as a determinant of appropriate action. However, we surveyed recent scholarly research and found that the role of intent is underappreciated or, often, wholly ignored during the annotation, detection, and in-practice moderation of online abuse.
- Capturing users’ intent from their text is an exceptionally hard problem. It is hard for a human reader to understand the intent of an author; it is even more challenging for an algorithm to do the same. Despite advancements in NLP, today’s state-of-the-art approaches cannot reliably infer user intent from short text, particularly if not provided with sufficient context. We highlight the features and metadata considered by existing algorithms, their prevalence, and their plausible impacts on understanding intent. Based on our findings, we put forth recommendations for the design of abuse detection and mitigation frameworks that include 1) robust training datasets annotated with context that reflect the complexities of intent, 2) state-of-the-art detection models that use contextual information as input and provide explanations as output, 3) moderation systems that combine automated detection with wisdom of the crowd to accommodate evolving social norms, and 4) friction-focused platform designs that both offer users opportunities to reflect on their intent before sharing and generate useful data regarding user intent.
Implications
Substantial interdisciplinary literature seeks to define, detect, measure, and model different types of abusive content online. Industry efforts to moderate abusive content at scale rely heavily on automated, algorithmic systems. These systems routinely fail (in terms of both false positives and false negatives). This paper explains why and proposes a series of potential improvements.
The basic argument is straightforward. Whether or not content is abusive, according to most platform policies and legal definitions, depends on the state of mind of a human being, usually the speaker. Yet algorithmic systems that process content (e.g., the speaker’s words) are unable to reliably determine a person’s state of mind. More and different kinds of information are needed.
The term abuse spans a spectrum of harmful language, including generalized hate speech and specific offenses such as sexism and racism. Definitions of different types of abuse often intersect and lack precise boundaries. Later, we consider various definitions and taxonomies proposed to describe abusive content.
Common to most definitions of digital abuse is some notion of intent (e.g., French et al., 2023; Hashemi, 2021; Molina et al., 2021; Vidgen & Derczynski, 2020). Intent is a subjective state of mind attributable to an actual person, typically the speaker, poster, or sharer. In cognitive science, ethics, law, and philosophy, intent is a contested and complicated concept. As Frischmann & Selinger (2018) explain:
Intention is a mental state that is part belief, part desire, and part value. My intention to do something—say to write th[is] explanatory text… or to eat an apple—entails (1) beliefs about the action, (2) desire to act, and (3) some sense of value attributable to the act (p. 364).
In pragmatic ethical and legal contexts, the focus often turns to evidence of intent. For example, a written signature is considered an objective manifestation that a person intends to enter into a contract (Frischmann & Vardi, 2024). Thus, by including intent in definitions of abusive content, the implicit challenge is divining subjective state of mind from evidence manifested in the content itself and the surrounding context.
While we focus on intent as a central element in how platforms define and moderate abuse, we do not claim that interpreting intent is the only or universally preferred approach. Some frameworks prioritize observable harms or outcomes, especially in contexts like mis- and disinformation (Mirza et al., 2023; Scheuerman et al., 2021). Our aim is not to displace these frameworks but to critically assess the feasibility and implications of relying on intent when it is embedded in platform policy and annotation practices.
Unsurprisingly, intent is exceedingly difficult to capture algorithmically through analysis of short text (Gao & Huang, 2017; MacAvaney et al., 2019; Wang et al., 2020). ToxicBERT (Hanu & Unitary team, 2020), for example, can label sentences as hateful or toxic but lacks the ability to interpret context in the input (MacAvaney et al., 2019; Wang et al., 2020). ToxicBERT flags the sentence “I’m going to kill you if you leave the dishes for me again” as toxic and threatening; it fails to differentiate between literal and figurative language. Supervised algorithms like ToxicBERT rely on curated, typically human-annotated training datasets. However, the complexities of intent are eventually reduced to simple class labels—such as hate speech or not hate speech. The underlying assumption of this approach is that human annotators are furnished with adequate contextual information to make these judgements.
In this paper, we survey the landscape of the online abuse moderation policies of major social media platforms. We examine existing taxonomies of online abuse and survey existing algorithms for abuse detection. We focus on hate speech and bullying due to their prevalence, but our work can and should be extended to other content categories for which intent is relevant, including mis-/disinformation (Kruger et al., 2024). We examine the training datasets underlying these algorithms and the role (if any) of intent during dataset annotation. Finally, we survey the set of features extracted from training datasets and used for algorithm development. These features reflect the varied context available to algorithmic content moderation systems. Our findings motivate a set of recommendations to better align abuse detection algorithms with platform policies (see Figure 1).
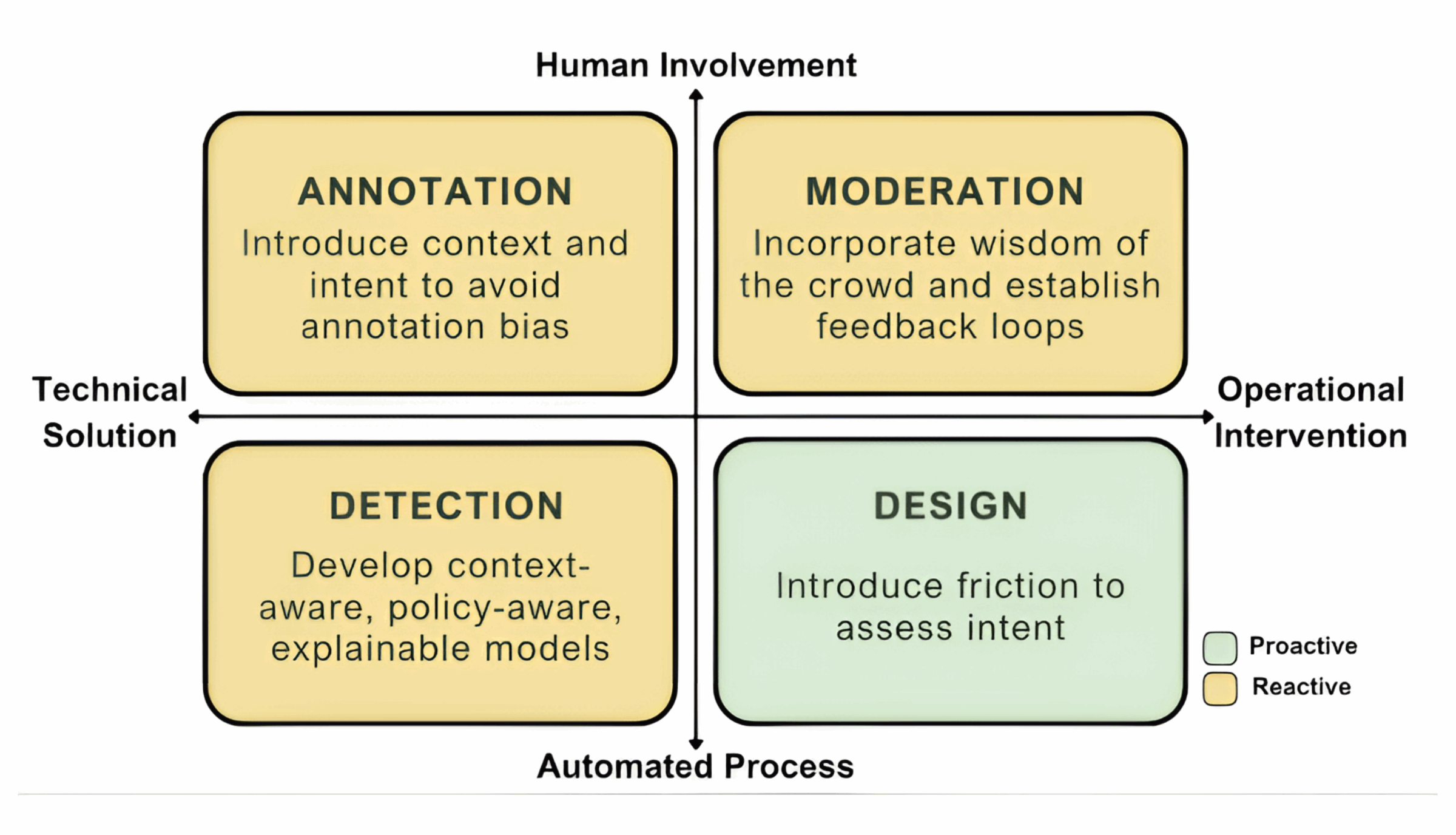
Recommendation: Annotation—Introduce context and intent during dataset annotation
Dataset curators must recognize social, cultural, and other contextual variations present in natural language, and design annotation tasks sensitive to and mindful of these differences. Moreover, dataset curators must provide sufficient context to annotators to permit accurate assessment of intent, in particular (Anuchitanukul & Ive, 2022). Examples of such context include conversation threads between initiators and targets, user history and metadata, or norms defined by the specific platform. We propose a combined codebook-datasheet in the form of a structured set of questions for dataset curators and annotators to consider prior to annotation—particularly for online abuse datasets. This framework integrates annotation-specific guidance (codebook) with dataset-level context (datasheet). The full set of questions is in Appendix A. Responses to these questions should be made transparent and explicit to all stakeholders prior to annotation. The structure of this framework is informed by qualitative approaches that treat annotation as an interpretive task shaped by context and ambiguity, rather than a purely objective labeling (Charmaz, 2006). By encouraging dataset curators and annotators to reflect on definitions, contextual cues, and the relationships between initiators and targets, the Codebook-Datasheet promotes more consistent and intent-sensitive annotation practices.
Challenge: Trade-offs between capturing intent and achieving high annotation agreement
A primary challenge in enhancing the annotation phase with contextual details is the trade-off between accurately inferring an individual’s intent reflected through content and maintaining high agreement among annotators (Ross et al., 2017). Context can be subjective, and different annotators might interpret the same information differently based on their backgrounds, experiences, and biases (Joseph et al., 2017; Lynn et al., 2019). Providing more context also raises concerns about privacy, annotator fatigue, and task scalability. On the other hand, annotator disagreements are sometimes due to lack of sufficient context (Zhang et al., 2023). In cases where intent is ambiguous, omitting context may lead to systematic mislabeling or overly reductive interpretations of the content. Consequently, establishing standardized guidelines that incorporate diverse perspectives is essential to mitigate this concern and improve annotation consistency.
Recommendation: Detection—Develop context-aware, policy-aware, explainable models
Incorporation of contextual features into detection algorithms can substantially improve the accuracy of intent-based abuse detection (Markov & Daelemans, 2022; Menini et al., 2021). Recent progress in NLP, such as the introduction of retrieval-augmented generation (RAG) for large language models (Li et al., 2024), supports access to relevant contextual information from knowledge bases—for example, a user’s past interactions—in real-time (Shi et al., 2024). Unlike earlier methods that rely on fixed input windows or static embeddings of prior conversations, RAG retrieves the most semantically relevant context dynamically, enabling more targeted and interpretable use of prior information. This may be especially beneficial for platforms aiming to implement context-aware moderation policies that adapt to dynamic social norms. Likewise, state-of-the-art large language models (LLMs) are more effective at executing rule-based moderation (Kumar et al., 2023); platform policies can be retrieved as context and used directly during the algorithmic decision process. Importantly, advances in explainable AI (XAI) should help users and developers understand model outputs (Islam et al., 2023; Kohli & Devi, 2023). Examples of XAI techniques include LIME, SHAP, and attention heatmaps, which help explain why a model flagged a post as abusive (Muhammadiah et al., 2025). These tools can help moderators identify whether misclassifications stem from sarcasm, missing context, or ambiguous language—factors especially relevant when intent is at the core. XAI can be used, for example, to pinpoint why a model might misunderstand particular intentions or contexts and ensure compliance with social media moderation policies that require explanations of AI-driven decisions. We advocate for the implementation of policy-aware and dynamic abuse detection, which can be facilitated by XAI and retrieval-augmented models.
Challenge: Balancing performance and applicability
Incorporating contextual features presents a significant challenge, particularly in terms of performance, as standard detection models often prove to be overly optimistic (Menini et al., 2021). Ensuring that the system achieves high performance without compromising its applicability can be difficult; thus, advanced machine learning models and continuous algorithm training with updated datasets are required to address this balance effectively (Scheuerman et al., 2021). Additionally, integrating XAI methods improves transparency, but they may also reduce model efficiency when requiring simplification of underlying architectures (Crook et al., 2023). Thus, designing explainability into systems without sacrificing model performance remains an ongoing area of research.
Recommendation: Moderation—Incorporate wisdom of the crowd and establish feedback loops
While algorithmic systems play an essential role in content moderation at scale, they also have limitations. Algorithms struggle to process and make sense of the nuance and subtlety of human communication (Bender & Koller, 2020). Humans, although generally better at understanding context and intent, can exhibit inconsistency and bias (Basile et al., 2022).
We suggest that moderation can be improved by hybrid approaches, leveraging “wisdom of the crowd”—utilizing user reports and community feedback—alongside, and even integrated with, algorithmic systems to identify and moderate abusive content (Allen et al., 2021; Pröllochs, 2022). The potential effectiveness of crowd-based moderation is evident in several real-world implementations, such as Twitter’s Birdwatch (now X’s Community Notes), where users collaboratively add contextual notes to potentially harmful or misleading content;1See: https://blog.x.com/en_us/topics/product/2021/introducing-birdwatch-a-community-based-approach-to-misinformation; https://help.x.com/en/using-x/community-notes Reddit’s voting and reporting mechanisms that shape content visibility;2 See: https://support.reddithelp.com/hc/en-us/articles/7419626610708-What-are-upvotes-and-downvotes; https://support.reddithelp.com/hc/en-us/articles/360058309512-How-do-I-report-a-post-or-comment and Wikipedia’s multi-layered editorial and review workflows.3See: https://en.wikipedia.org/wiki/Wikipedia:Editing_policy Additionally, we recommend establishing clear pathways for feedback so that moderators can provide insights back to the automated detection systems to support iterative improvements, for example, as new labeled training data. Throughout these processes, platforms must design moderation systems to be sensitive to evolving definitions of inappropriate content and dynamic societal norms across regions and cultures.
Challenge: Managing the scale and the biases inherent in crowd-sourced moderation
The challenge in this phase lies in managing the scale of data and potential biases that can arise from crowd-sourced inputs. User reports can be influenced by personal biases or coordinated attacks, leading to false positives or negatives (Jhaver et al., 2019). Uneven participation rates mean that moderation decisions may disproportionately reflect the views of a narrow group of users. Moreover, the quality of crowd input may vary widely depending on task design, interface clarity, and community norms (Gadiraju et al., 2015). Implementing robust filtering algorithms to verify and validate user-generated reports before they influence the moderation process is crucial for maintaining the integrity of the system.
Recommendation: Design—Introduce friction to generate evidence of intent and enable more intentional actions
For the most part, we focus on the detection and evaluation of content flowing through social media systems as if the moderation pipeline is designed to operate independently, only triggering governance procedures upon detection of content that violates a policy. Of course, the actions of users depend to some degree on the affordances of the social media platform itself.
If we relax the assumption of independence between platform design and content moderation pipeline design, a range of friction-in-design (Frischmann & Selinger, 2018; Frischmann & Benesch, 2023) measures might generate reliable evidence of intent to better guide content moderation systems. For example, platforms might introduce prompts that query users about their intentions when users post or share (certain types of) content. Such prompts might be triggered based on different criteria, such as accuracy, authenticity, or intended audience. The prompt could provide a simple means for the user to express their intentions. The prompt might be framed in terms of purpose. Not only would a response provide potentially reliable evidence of intent that would be useful for moderation, but it also would provide the user with an opportunity to think about their own intentions. Other friction-in-design measures could provide users with knowledge about the potential consequences of their actions. Such measures would generate another source of reliable evidence about intent.
Prior research has shown that friction-based interventions—such as prompts during content creation, interstitial warnings, limits on message forwarding, and credibility nudges—can reduce misinformation sharing, offensive language, and improve user reflection (Clayton et al., 2020; Egelman et al., 2008; Fazio, 2020; Jahn et al., 2023; Kaiser et al., 2021). These examples underscore that friction can support both behavioral change and the elicitation of user intent for moderation purposes.
Challenge: Aligning business models and regulatory frameworks with slow governance for a safe, healthy digital environment
The basic idea of the friction-in-design strategy is to focus on the dynamic interactions between the social media platform and the content moderation pipeline from a design perspective. The associated challenges here are substantively different from the technical challenges we have outlined in prior sections. The success of friction-in-design approaches center around platform business models and regulatory frameworks that prioritize and reward healthy information ecosystems (Frischmann & Benesch, 2023). Frischmann & Sanfilippo (2023) emphasize the need to replace the dominant platform design logic that prioritizes frictionless, seamless interactions with one that embraces slow governance. Here, what that means is utilizing digital speedbumps not only to slow traffic but also, more importantly, for the instrumental functions of generating reliable evidence of intent and affording users the opportunity to be more intentional in their online behavior. Yet, as is probably all too obvious, this presents a fundamental challenge to existing business models.
Findings
Finding 1: Existing taxonomies of digital abuse are diverse and often ambiguous, making consistent categorization difficult.
Extensive literature details the diverse forms of online harm across various digital platforms (e.g., Arora et al., 2023; Im et al., 2022; Keipi et al., 2016; Scheuerman et al., 2021). These studies categorize a range of abusive speech, with prominent themes including hate speech, cyberbullying, and discrimination (Arora et al., 2023; Ghosh et al., 2024; Scheuerman et al., 2021). Each of these harms is consequent to nuanced user interactions, which are often platform-specific, culture-sensitive, and context-dependent. Prior work has highlighted the differing definitions of online harms in the literature (Fortuna & Nunes, 2018); this ambiguity poses challenges for the development of consistent and effective moderation pipelines.
Various approaches to classifying online abuse emphasize different parameters. Some taxonomies highlight the target of abuse—whether directed at individuals, groups, or concepts (Al Mazari, 2013; Vidgen et al., 2019; Waseem et al., 2017). Others focus on characteristics of the abuse—whether it is explicit or implicit (Mladenović et al., 2021), and still others explore subcategories of abuse or harm (Gashroo & Mehrotra, 2022; Lewandowska-Tomaszczyk et al., 2023). An overview of existing taxonomies is provided in Appendix B. Our work focuses on intent, which features prominently in platform policies but is often implicit in current taxonomies. For example, intent may be operationalized through the notion of targeting. We emphasize two common types of explicit online abuse: hate speech and cyberbullying (Wiegand et al., 2019). These forms of abuse have not only received significant attention in natural language processing (NLP) but reflect intent—deliberate aim to harm or intimidate specific individuals or groups. To clarify how these categories are typically defined in the literature, we provide the following commonly used definitions:
- Hate speech: speech that attacks or discriminates against a person or group on the basis of attributes such as race, religion, ethnic origin, national origin, sex, disability, sexual orientation, or gender identity (Brown, 2017; Lepoutre et al., 2023)
- Cyberbullying: the use of electronic communication technologies like the internet, social media, and mobile phones to intentionally harass, threaten, humiliate, or target another person or group (Campbell & Bauman, 2018; Wright, 2021)
Finding 2: Platform moderation policies invoke user intent, yet intent is difficult to observe directly.
Intentions are a state of mind. People exercise their autonomy by acting upon their intentions. Most often, we rely on external manifestations, such as what people say or do (Frischmann & Selinger, 2018) to learn another person’s intent. In content moderation, like other contexts, intent is thus inexorably intertwined with actions. When attempting to determine the intent associated with abusive content, one must identify the relevant actor(s) and action(s). Notably, content is a sociotechnical artifact with history and context, and multiple relevant actors and actions may be involved with its arrival in the platform. Major platforms like Twitter (now “X”) and Facebook (now “Meta”) emphasize the importance of intent in content moderation. For example, Twitter’s guidelines state (emphasis added):
Violent entities are those that deliberately target humans or essential infrastructure with physical violence and/or violent rhetoric as a means to further their cause.
Hateful entities are those that have systematically and intentionally promoted, supported and/or advocated for hateful conduct, which includes promoting violence or engaging in targeted harassment towards a protected category.4See: https://help.Twitter.com/en/rules-and-policies/violent-entities (accessed May 2024).
Instagram also addresses the complexity of moderating hate speech by considering the intent associated with the act of sharing. The platform allows content that might be deemed hateful if it is shared to challenge or raise awareness about the issues discussed, provided this intent is clearly communicated (emphasis added):
It’s never OK to encourage violence or attack anyone based on their race, ethnicity, national origin, sex, gender, gender identity, sexual orientation, religious affiliation, disabilities, or diseases. When hate speech is being shared to challenge it or to raise awareness, we may allow it. In those instances, we ask that you express your intent clearly.5See: https://help.instagram.com/477434105621119 (accessed May 2024).
TikTok describes hate speech as intentional as well (emphasis added):
( … ) content that intends to or does attack, threaten, incite violence against, or dehumanize an individual or group of individuals on the basis of protected attributes like race, religion, gender, gender identity, national origin, and more.6See: https://newsroom.tiktok.com/en-us/countering-hate-on-tiktok (accessed May 2024).
Finding 3: Many publicly available datasets of abusive content lack detailed annotation procedures and do not systematically incorporate intent or platform-specific context.
Our review highlights several key challenges to the alignment between platforms’ policies around abuse and the datasets used to train abuse detection algorithms:
- Ambiguity in definitions of digital abuse: Compounding the diversity of definitions and taxonomies of abuse proposed in academic work and discussed above, instructions to annotators are often vague. This can result in lack of reusable training data and benchmarks. In Figure 2, we provide excerpts describing annotation processes from surveyed papers. While we cannot determine whether more comprehensive information was provided to annotators due to limited reporting, excerpts alone reveal substantial variability in definitions and instructions.

- Inconsistent consideration of intent during annotation: Table 1 shows an excerpt from the dataset paper summary (see Appendix D for the full table).Of the dataset papers surveyed, 47.6% (20 of 42) explicitly mentioned intent during annotation, while 35.7% (15 of 42) provided context to annotators to help them better infer intent. In addition, 33.3% (14 of 42) of the papers required annotators to identify the target of abuse. Just three papers (Van Hee et al., 2018; Vidgen, Nguyen, et al., 2021; Ziems et al., 2020) provided contextual information to annotators, explicitly acknowledged the role of intent in annotation guidelines, and requested annotators to identify the target of the abuse.
- Cross-platform differences: Text and annotation instructions are typically provided to annotators outside of the platforms from which they were collected. Labels are considered universal, rather than tailored to the environments and operational settings of specific social media platforms.
| Reference | Source | Author-defined scope | Content type | Context provided | Target annotation | Intent mentioned |
| (Waseem & Hovy, 2016) | Hate Speech | Text | No | No | No | |
| (Waseem, 2016) | Hate Speech | Text | No | No | No | |
| (Golbeck et al., 2017) | Online Harassment | Text | No | No | Yes | |
| (Chatzakou et al., 2017) | Cyberbullying | Multimodal | Metadata | No | Yes | |
| (Gao & Huang, 2017) | Fox News | Hate Speech | Text | Conversation | No | No |
| (Davidson et al., 2017) | Hate Speech | Text | No | No | Yes | |
| (Gao et al., 2017) | Hate Speech | Text | No | No | No | |
| (Jha & Mamidi, 2017) | Sexism | Text | No | No | No | |
| (Van Hee et al., 2018) | ASKfm | Cyberbullying | Text | Conversation | Yes | Yes |
| (Fersini et al., 2018) | Misogyny | Text | No | Yes | Yes |
Finding 4: Current detection algorithms often fail to account for contextual and dynamic aspects of hate speech and cyberbullying, limiting their ability to infer intent and generalize across settings.
We prompted GPT-3.5 to classify several statements as abusive or not abusive, both with and without contextual cues (see Figure 3). We used GPT-3.5 because it is a widely available, general-purpose language model that can respond to contextual prompts, allowing us to observe how variations in context and intent may affect classification outcomes. We observe the impact of context and intention on model interpretations of each statement. However, many existing models, like those based on BERT, fall short in capturing context to infer intent. We evaluated four different models (Barbieri et al., 2020; Das et al., 2022; Mathew et al., 2021; Vidgen, Thrush, et al., 2021) using the same examples as those tested with GPT-3.5. The results (see Figure 3) show inconsistent outputs and a significant reliance on word-level cues, failing to account for the underlying user intent that contextualizes meaning.
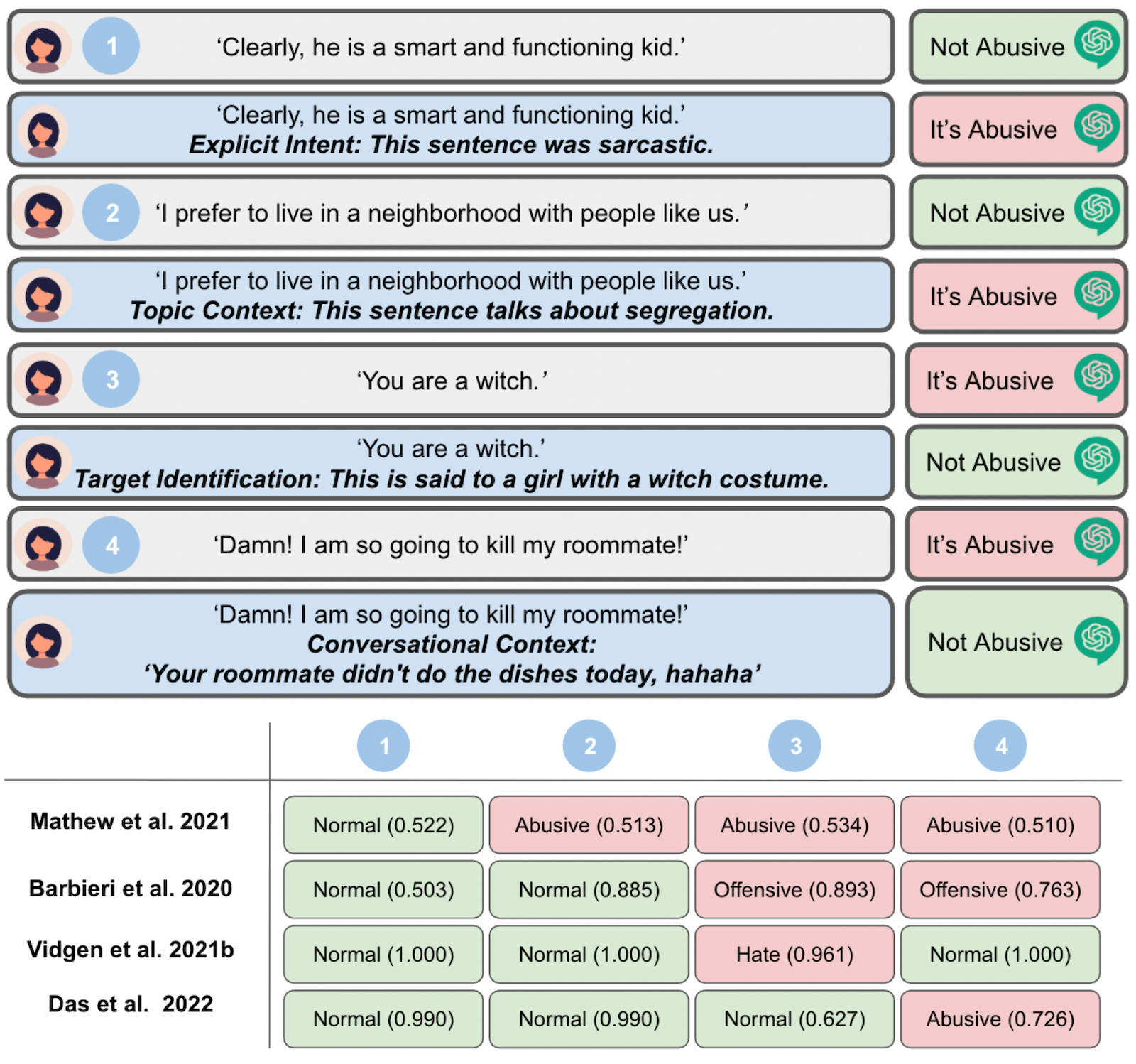
Our context analysis of the papers on online abuse detection algorithms confirmed that while detection models have made notable advances in identifying abusive content through analysis of textual data, they often fail to consider the complex nature of social media interactions, which include aspects like user status, social network structures, and offline context. Figure 4(A) shows the co-occurrence network of ten features extracted and used to capture context and infer intent. The size of each node reflects how many papers included the corresponding feature, while the width of each edge represents how often two features appeared together in the same paper. We observe that user metadata are the most frequently considered features, with 16 (9.5%) algorithms using them for detection. Similarly, linguistic cues are used in 14 (8.3%) studies and post metadata in 10 (5.9%). In contrast, psychological and cognitive dimensions, and policy or rule-aware models are less frequently explored, with just four (2.2%) and two (1.1%) studies, respectively. A majority of reviewed papers, 58.9% (99 of 168), focus on comparing model performance and benchmarking against various metrics. Figure 4(B) shows a histogram of papers according to the number of intent-related features considered in a paper. Among 168 surveyed papers, three of them present models incorporating six out of the ten features listed above, meaningfully including context and potentially addressing the issue of intent (Dhingra et al., 2023; López-Vizcaíno et al., 2021; Ziems et al., 2020). Building upon Ziems et al. (2020), a subsequent paper utilized the dataset from the earlier study and applied methodological improvements (Dhingra et al., 2023).

Based on these observations and our review of the literature, we summarized the current limitations of detection algorithms for online abuse.
- Insufficient context for inferring intent: Because intent is rarely explicit in language, detecting it often requires additional context beyond the text itself. Traditional text-based models, though robust in their linguistic analyses, fall short in understanding the complexities of group dynamics in the spread of online abuse (Salminen et al., 2018). For instance, an abusive narrative might emerge and propagate not merely because of its textual content but due to the influence and endorsement of a closely-knit group within the network (Marwick & Lewis, 2017). These group-based interactions are influenced by, for example, shared ideologies, mutual affiliations, or even orchestrated campaigns, which sometimes employ subtle linguistic cues not easily detectable by conventional text-based models. The complexity is further compounded when they employ tactics like code-switching, euphemisms, or meme-based communication, thereby effectively circumventing text-based detection mechanisms.
- Static perspectives: Social norms are dynamic and influence users’ interpretation of what constitutes abusive content (Crandall et al., 2002). Traditional detection models often fail to account for these longitudinal shifts. For example, a phrase may take on a new meaning in the digital realm, and the rapid evolution of internet slang also necessitates a more flexible approach for continuous training and updating.
- Poor generalizability: Model performance can fluctuate significantly even when utilizing the same dataset, with optimal outcomes frequently exclusive to that specific dataset (Leo et al., 2023). These inconsistencies highlight the need for robust testing to understand the generalizability of existing methods in new contexts.
Methods
Online abuse datasets
We reviewed the documentation provided in the associated papers of existing online abuse detection datasets, focusing on any available descriptions of data sources, categories, modality, and annotation procedures. We categorize each based on the extent to which it considers the context and intent of abusive expressions during annotation. We reviewed papers available between 2016 and 2024 using Scopus search along with datasets referenced in Vidgen & Derczynski (2020).7See: https://hatespeechdata.com/ (accessed May 2024) and citation search. The dataset selection and review process involved two researchers. One researcher drafted the initial table, and the second independently reviewed the associated papers in detail to identify any discrepancies. No inconsistencies were observed during this process. Further details, search terms, inclusion criteria, and a PRISMA diagram for the screening pipeline are provided in Appendix C.
Appendix D outlines papers reviewed, noting whether any contextual information was provided to annotators, whether intent was explicitly mentioned in annotation instructions, and whether the annotation task included identification of a target person or group.
- Intent mentioned: We capture whether annotation guidelines mention intent, intention, etc., anywhere in instructions or definitions.
- Context provided: When provided, context takes one of two forms: 1) conversations (annotators are provided with conversation/text surrounding the text being annotated, enabling them to infer intent by understanding the broader exchange) and 2) metadata (annotators are provided with user-level metadata, for example, profile content, geographical location, or post-level metadata, for example, images or text extracted from images, which may offer additional clues about intent).
- Target annotation: Annotation guidelines request that the person or group targeted by a comment be identified during annotation.
Online abuse detection algorithms
We reviewed the papers that described and examined abuse detection models, categorized features utilized by these models, and identified the gaps that exist in effectively detecting abuse. We queried SCOPUS for papers presenting abuse detection algorithms published between 2013 and early 2024. Similar to our survey of datasets, specific search terms, inclusion criteria, and a PRISMA diagram for the screening pipeline are provided in Appendix C. The review and categorization were also conducted by two researchers who cross-checked decisions and engaged in discussion to ensure consistency. No inconsistencies were reported during this process.
We categorized the features used by detection models in our survey that go beyond traditional text-based methods such as bag-of-words, TF-IDF, and embeddings. These features fall into the following ten categories: user metadata, post metadata, image and video content, psychological and cognitive signals, conversational context, graph structure, policy- or rule-aware signals, sentiment, topical or thematic information, and linguistic cues. Appendix E provides a detailed breakdown and examples for each category, and Appendix F includes a full mapping of these features to the corresponding papers in our survey.
Topics
Bibliography
Al Mazari, A. (2013). Cyber-bullying taxonomies: Definition, forms, consequences and mitigation strategies. In 2013 5th International Conference on Computer Science and Information Technology (pp. 126–133). IEEE. https://doi.org/10.1109/CSIT.2013.6588770
Albanyan, A., & Blanco, E. (2022). Pinpointing fine-grained relationships between hateful tweets and replies. Proceedings of the AAAI Conference on Artificial Intelligence, 36(10), 10418–10426. https://doi.org/10.1609/aaai.v36i10.21284
Albanyan, A., Hassan, A., & Blanco, E. (2023). Not all counterhate tweets elicit the same replies: A fine-grained analysis. In A. Palmer & J. Camacho-Collados (Eds.), Proceedings of the 12th Joint Conference on Lexical and Computational Semantics (*SEM 2023) (pp. 71–88). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.starsem-1.8
Ali, S., Blackburn, J., & Stringhini, G. (2025). Evolving hate speech online: An adaptive framework for detection and mitigation. arXiv. https://doi.org/10.48550/arXiv.2502.10921
Allen, J., Arechar, A. A., Pennycook, G., & Rand, D. G. (2021). Scaling up fact-checking using the wisdom of crowds. Science Advances, 7(36), eabf4393. https://doi.org/10.1126/sciadv.abf4393
Anuchitanukul, A., & Ive, J. (2022). SURF: Semantic-level unsupervised reward function for machine translation. In M. Carpuat, M.-C. de Marneffe, & I. V. Meza Ruiz (Eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4508–4522). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.naacl-main.334
Arora, A., Nakov, P., Hardalov, M., Sarwar, S. M., Nayak, V., Dinkov, Y., Zlatkova, D., Dent, K., Bhatawdekar, A., Bouchard, G., & Augenstein, I. (2023). Detecting harmful content on online platforms: What platforms need vs. Where research efforts go. ACM Computing Surveys, 56(3), 1–17. https://doi.org/10.1145/3603399
Barbieri, F., Camacho-Collados, J., Espinosa Anke, L., & Neves, L. (2020). TweetEval: Unified benchmark and comparative evaluation for tweet classification. In T. Cohn, Y. He, & Y. Liu (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2020 (pp. 1644–1650). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.findings-emnlp.148
Basile, V., Bosco, C., Fersini, E., Nozza, D., Patti, V., Rangel Pardo, F. M., Rosso, P., & Sanguinetti, M. (2019). SemEval-2019 Task 5: Multilingual detection of hate speech against immigrants and women in Twitter. In J. May, E. Shutova, A. Herbelot, X. Zhu, M. Apidianaki, & S. M. Mohammad (Eds.), Proceedings of the 13th International Workshop on Semantic Evaluation (pp. 54–63). Association for Computational Linguistics. https://doi.org/10.18653/v1/S19-2007
Basile, V., Caselli, T., Balahur, A., & Ku, L.-W. (2022). Bias, subjectivity and perspectives in natural language processing. Frontiers in Artificial Intelligence, 5, 926435. https://doi.org/10.3389/frai.2022.926435
Bender, E. M., & Koller, A. (2020). Climbing towards NLU: On meaning, form, and understanding in the age of data. In D. Jurafsky, J. Chai, N. Schluter, & J. Tetreault (Eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 5185–5198). Association for Computational Linguistics. https://doi.org/10.18653/v1/2020.acl-main.463
Brown, A. (2017). What is hate speech? Part 1: The myth of hate. Law and Philosophy, 36, 419–468. https://doi.org/10.1007/s10982-017-9297-1
Campbell, M., & Bauman, S. (2018). Cyberbullying: Definition, consequences, prevalence. In Reducing cyberbullying in schools (pp. 3–16). Elsevier. https://doi.org/10.1016/B978-0-12-811423-0.00001-8
Caselli, T., Basile, V., Mitrović, J., Kartoziya, I., & Granitzer, M. (2020). I feel offended, don’t be abusive! Implicit/explicit messages in offensive and abusive language. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Twelfth Language Resources and Evaluation Conference (pp. 6193–6202). European Languages Resources Association. https://aclanthology.org/2020.lrec-1.760/
Charmaz, K. (2006). Constructing grounded theory: A practical guide through qualitative analysis. SAGE.
Clayton, K., Blair, S., Busam, J. A., Forstner, S., Glance, J., Green, G., Kawata, A., Kovvuri, A., Martin, J., Morgan, E., Sandhu, M., Sang, R., Scholz-Bright, R., Welch, A. T., Wolff, A. G., Zhou, A., & Nyhan, B. (2020). Real solutions for fake news? Measuring the effectiveness of general warnings and fact-check tags in reducing belief in false stories on social media. Political Behavior, 42(4), 1073–1095. https://doi.org/10.1007/s11109-019-09533-0
Crandall, C. S., Eshleman, A., & O’Brien, L. (2002). Social norms and the expression and suppression of prejudice: The struggle for internalization. Journal of Personality and Social Psychology, 82(3), 359–78. https://pubmed.ncbi.nlm.nih.gov/11902622/
Crook, B., Schlüter, M., & Speith, T. (2023). Revisiting the performance-explainability trade-off in explainable artificial intelligence (XAI). arXiv. https://doi.org/10.48550/arXiv.2307.14239
Das, M., Banerjee, S., & Mukherjee, A. (2022). Data bootstrapping approaches to improve low resource abusive language detection for Indic languages. arXiv. https://doi.org/10.48550/arXiv.2204.12543
Dhingra, N., Chawla, S., Saini, O., & Kaushal, R. (2023). An improved detection of cyberbullying on social media using randomized sampling. International Journal of Bullying Prevention, 1–13. https://doi.org/10.1007/s42380-023-00188-4
Egelman, S., Cranor, L. F., & Hong, J. (2008). You’ve been warned: An empirical study of the effectiveness of web browser phishing warnings. In CHI ’08: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 1065–1074). Association for Computing Machinery. https://doi.org/10.1145/1357054.1357219
Fazio, L. (2020). Pausing to consider why a headline is true or false can help reduce the sharing of false news. Harvard Kennedy School (HKS) Misinformation Review, 1(2). https://doi.org/10.37016/mr-2020-009
Fortuna, P., & Nunes, S. (2018). A survey on automatic detection of hate speech in text. ACM Computing Surveys (CSUR), 51(4), 1–30. https://doi.org/10.1145/3232676
French, A., Storey, V. C., & Wallace, L. (2023). A typology of disinformation intentionality and impact. Information Systems Journal, 34(4), 1324–1354. https://doi.org/10.1111/isj.12495
Frischmann, B., & Benesch, S. (2023). Friction-in-design regulation as 21st century time, place, and manner restriction. Yale Journal of Law and Technology, 25(1), 376–447. https://yjolt.org/friction-design-regulation-21st-century-time-place-and-manner-restriction
Frischmann, B. M., & Vardi, M. Y. (2024). Better digital contracts with prosocial friction-in-design. SSRN. http://dx.doi.org/10.2139/ssrn.4918003
Frischmann, B., & Sanfilippo, M. (2023). Slow-governance in smart cities: An empirical study of smart intersection implementation in four U. S. college towns. Internet Policy Review, 12(1), 1–31. https://doi.org/10.14763/2023.1.1703
Frischmann, B., & Selinger, E. (2018). Re-engineering humanity. Cambridge University Press. https://doi.org/10.1017/9781316544846
Gadiraju, U., Kawase, R., Dietze, S., & Demartini, G. (2015). Understanding malicious behavior in crowdsourcing platforms: The case of online surveys. In CHI ’15: Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (pp. 1631–1640). Association for Computing Machinery. https://doi.org/10.1145/2702123.2702443
Gao, L., & Huang, R. (2017). Detecting online hate speech using context aware models. In R. Mitkov & G. Angelova (Eds.), Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017 (pp. 260–266). INCOMA Ltd. https://doi.org/10.26615/978-954-452-049-6_036
Gashroo, O. B., & Mehrotra, M. (2022). Analysis and classification of abusive textual content detection in online social media. In G. Rajakumar, K. Du, C. Vuppalapati, & G. N. Beligiannis (Eds.), Intelligent Communication Technologies and Virtual Mobile Networks: Proceedings of ICICV 2022 (pp. 173–190). Springer. https://doi.org/10.1007/978-981-19-1844-5_15
Ghosh, S., Venkit, P. N., Gautam, S., Wilson, S., & Caliskan, A. (2024). Do generative ai models output harm while representing non-western cultures: Evidence from a community-centered approach. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society (pp. 476–489). AAAI Press. https://dl.acm.org/doi/10.5555/3716662.3716702
Grimminger, L., & Klinger, R. (2021). Hate towards the political opponent: A Twitter corpus study of the 2020 us elections on the basis of offensive speech and stance detection. In O. De Clercq, A. Balahur, J. Sedoc, V. Barriere, S. Tafreshi, S. Buechel, & V. Hoste (Eds.), Proceedings of the Eleventh Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis (pp. 171–180). Association for Computational Linguistics. https://aclanthology.org/2021.wassa-1.18
Hanu, L. & Unitary team. (2020). Detoxify. Github. https://github.com/unitaryai/detoxify
Hashemi, M. (2021). A data-driven framework for coding the intent and extent of political tweeting, disinformation, and extremism. Information, 12(4), 148. https://doi.org/10.3390/info12040148
Im, J., Schoenebeck, S., Iriarte, M., Grill, G., Wilkinson, D., Batool, A., Alharbi, R., Funwie, A., Gankhuu, T., Gilbert, E., & Naseem, M. (2022). Women’s perspectives on harm and justice after online harassment. Proceedings of the ACM on Human-Computer Interaction, 6(CSCW2), 1–23. https://doi.org/10.1145/3555775
Islam, M. R., Bataineh, A. S., & Zulkernine, M. (2023). Detection of cyberbullying in social media texts using explainable artificial intelligence. In G. Wang, H. Wang, G. Min, N. Georgalas, & W. Meng (Eds.), Ubiquitous Security: UbiSec 2023 (pp. 319–334). Springer. https://doi.org/10.1007/978-981-97-1274-8_21
Jha, A., & Mamidi, R. (2017). When does a compliment become sexist? Analysis and classification of ambivalent sexism using Twitter data. In D. Hovy, S. Volkova, D. Bamman, D. Jurgens, B. O’Connor, O. Tsur, & A. S. Doğruöz (Eds.), Proceedings of the Second Workshop on NLP and Computational Social Science (pp. 7–16). Association for Computational Linguistics. https://doi.org/10.18653/v1/W17-2902
Jhaver, S., Birman, I., Gilbert, E., & Bruckman, A. (2019). Human-machine collaboration for content regulation: The case of reddit automoderator. ACM Transactions on Computer-Human Interaction, 26(5), 1–35. https://doi.org/10.1145/3338243
Joseph, K., Friedland, L., Hobbs, W., Lazer, D., & Tsur, O. (2017). ConStance: Modeling annotation contexts to improve stance classification. In M. Palmer, R. Hwa, & S. Riedel (Eds.), Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (pp. 1115–1124). Association for Computational Linguistics. https://doi.org/10.18653/v1/D17-1116
Kaiser, B., Wei, J., Lucherini, E., Lee, K., Matias, J. N., & Mayer, J. (2021). Adapting security warnings to counter online disinformation. In 30th USENIX Security Symposium (USENIX Security 21) (pp. 1163–1180). https://www.usenix.org/conference/usenixsecurity21/presentation/kaiser
Keipi, T., Näsi, M., Oksanen, A., & Räsänen, P. (2016). Online hate and harmful content: Cross-national perspectives. Taylor & Francis.
Kohli, A., & Devi, V. S. (2023). Explainable offensive language classifier. In B. Luo, L. Cheng, Z.-G. Wu, H. Li, & C. Li (Eds.), International Conference on Neural Information Processing (pp. 299–313). Springer. http://dx.doi.org/10.1007/978-981-99-8132-8_23
Kruger, A., Saletta, M., Ahmad, A., & Howe, P. (2024). Structured expert elicitation on disinformation, misinformation, and malign influence: Barriers, strategies, and opportunities. Harvard Kennedy School (HKS) Misinformation Review, 5(7). https://doi.org/10.37016/mr-2020-169
Kumar, D., AbuHashem, Y., & Durumeric, Z. (2023). Watch your language: Investgating content moderation with large language models. arXiv. https://doi.org/10.48550/arXiv.2309.14517
Leo, C. O., Santoso, B. J., & Pratomo, B. A. (2023). Enhancing hate speech detection for social media moderation: A comparative analysis of machine learning algorithms. In 2023 International Conference on Advanced Mechatronics, Intelligent Manufacture and Industrial Automation (ICAMIMIA) (pp. 960–964). IEEE. https://doi.org/10.1109/ICAMIMIA60881.2023.10427779
Lepoutre, M., Vilar-Lluch, S., Borg, E., & Hansen, N. (2023). What is hate speech? The case for a corpus approach. Criminal Law and Philosophy, 1–34. https://doi.org/10.1007/s11572-023-09675-7
Lewandowska-Tomaszczyk, B., Bączkowska, A., Liebeskind, C., Valunaite Oleskeviciene, G., & Žitnik, S. (2023). An integrated explicit and implicit offensive language taxonomy. Lodz Papers in Pragmatics, 19(1), 7–48. https://doi.org/10.1515/lpp-2023-0002
Li, G., Lu, W., Zhang, W., Lian, D., Lu, K., Mao, R., Shu, K., & Liao, H. (2024). Re-search for the truth: Multi-round retrieval-augmented large language models are strong fake news detectors. arXiv. https://doi.org/10.48550/arXiv.2403.09747
López-Vizcaíno, M. F., Nóvoa, F. J., Carneiro, V., & Cacheda, F. (2021). Early detection of cyberbullying on social media networks. Future Generation Computer Systems, 118, 219–229. https://doi.org/10.1016/j.future.2021.01.00
Lynn, V., Giorgi, S., Balasubramanian, N., & Schwartz, H. A. (2019). Tweet classification without the tweet: An empirical examination of user versus document attributes. In S. Volkova, D. Jurgens, D. Hovy, D. Bamman, & O. Tsur (Eds.), Proceedings of the Third Workshop on Natural Language Processing and Computational Social Science (pp. 18–28). Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-2103
MacAvaney, S., Yao, H.-R., Yang, E., Russell, K., Goharian, N., & Frieder, O. (2019). Hate speech detection: Challenges and solutions. PLoS ONE, 14(8). https://doi.org/10.1371/journal.pone.0221152
Mahadevan, A., & Mathioudakis, M. (2024). Cost-aware retraining for machine learning. Knowledge-Based Systems, 293, 111610. https://doi.org/10.1016/j.knosys.2024.111610
Markov, I., & Daelemans, W. (2022). The role of context in detecting the target of hate speech. In R. Kumar, A. Kr. Ojha, M. Zampieri, S. Malmasi, & D. Kadar (Eds.), Proceedings of the Third Workshop on Threat, Aggression and Cyberbullying (TRAC 2022) (pp. 37–42). Association for Computational Linguistics. https://aclanthology.org/2022.trac-1.5
Marwick, A., & Lewis, R. (2017). Media manipulation and disinformation online. Data & Society. https://datasociety.net/library/media-manipulation-and-disinfo-online/
Mathew, B., Saha, P., Yimam, S. M., Biemann, C., Goyal, P., & Mukherjee, A. (2021). Hatexplain: A benchmark dataset for explainable hate speech detection. Proceedings of the AAAI Conference on Artificial Intelligence, 35(17), 14867–14875. https://cdn.aaai.org/ojs/17745/17745-13-21239-1-2-20210518.pdf
Menini, S., Aprosio, A. P., & Tonelli, S. (2021). Abuse is contextual, what about nlp? The role of context in abusive language annotation and detection. arXiv. https://doi.org/10.48550/arXiv.2103.14916
Mirza, S., Begum, L., Niu, L., Pardo, S., Abouzied, A., Papotti, P., & Pöpper, C. (2023). Tactics, threats & targets: Modeling disinformation and its mitigation [Paper presentation]. 2023 Network and Distributed System Security Symposium. San Diego, CA, USA. https://doi.org/10.14722/ndss.2023.23657
Mladenović, M., Ošmjanski, V., & Stanković, S. V. (2021). Cyber-aggression, cyberbullying, and cyber-grooming: A survey and research challenges. ACM Computing Surveys (CSUR), 54(1), 1–42. https://doi.org/10.1145/3424246
Molina, M. D., Sundar, S. S., Le, T., & Lee, D. (2021). “Fake news” is not simply false information: A concept explication and taxonomy of online content. American Behavioral Scientist, 65(2), 180–212. https://doi.org/10.1177/0002764219878224
Muhammadiah, M., Rahman, R., & Wei, S. (2025). Interpretation of deep learning models in natural language processing for misinformation detection with the explainable AI (XAI) approach. Journal of Computer Science Advancements, 3(2), 2. https://doi.org/10.70177/jsca.v3i2.2104
Pröllochs, N. (2022). Community-based fact-checking on Twitter’s birdwatch platform. Proceedings of the International AAAI Conference on Web and Social Media, 16, 794–805. https://doi.org/10.1609/icwsm.v16i1.19335
Ross, B., Rist, M., Carbonell, G., Cabrera, B., Kurowsky, N., & Wojatzki, M. (2017). Measuring the reliability of hate speech annotations: The case of the European refugee crisis. arXiv. https://doi.org/10.17185/duepublico/42132
Salminen, J., Almerekhi, H., Milenković, M., Jung, S., An, J., Kwak, H., & Jansen, B. (2018). Anatomy of online hate: Developing a taxonomy and machine learning models for identifying and classifying hate in online news media. Proceedings of the International AAAI Conference on Web and Social Media, 12(1). https://doi.org/10.1609/icwsm.v12i1.15028
Scheuerman, M. K., Jiang, J. A., Fiesler, C., & Brubaker, J. R. (2021). A framework of severity for harmful content online. Proceedings of the ACM on Human-Computer Interaction, 5(CSCW2), 1–33. https://doi.org/10.1145/3479512
Shi, K., Sun, X., Li, Q., & Xu, G. (2024). Compressing long context for enhancing RAG with AMR-based concept distillation. arXiv. https://doi.org/10.48550/arXiv.2405.03085
Toraman, C., Şahinuç, F., & Yilmaz, E. (2022). Large-scale hate speech detection with cross-domain transfer. In N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, J. Odijk, & S. Piperidis (Eds.), Proceedings of the Thirteenth Language Resources and Evaluation Conference (pp. 2215–2225). European Language Resources Association. https://aclanthology.org/2022.lrec-1.238
Van Hee, C., Jacobs, G., Emmery, C., Desmet, B., Lefever, E., Verhoeven, B., De Pauw, G., Daelemans, W., & Hoste, V. (2018). Automatic detection of cyberbullying in social media text. PloS One, 13(10), e0203794. https://doi.org/10.1371/journal.pone.0203794
Vidgen, B., & Derczynski, L. (2020). Directions in abusive language training data, a systematic review: Garbage in, garbage out. PloS One, 15(12), e0243300. https://doi.org/10.1371/journal.pone.0243300
Vidgen, B., Harris, A., Nguyen, D., Tromble, R., Hale, S., & Margetts, H. (2019). Challenges and frontiers in abusive content detection. In S. T. Roberts, J. Tetreault, V. Prabhakaran, & Z. Waseem (Eds.), Proceedings of the Third Workshop on Abusive Language Online (pp. 80–93). Association for Computational Linguistics. https://doi.org/10.18653/v1/W19-3509
Vidgen, B., Nguyen, D., Margetts, H., Rossini, P., & Tromble, R. (2021). Introducing CAD: The contextual zbuse dataset. In K. Toutanova, A. Rumshisky, L. Zettlemoyer, D. Hakkani-Tur, I. Beltagy, S. Bethard, R. Cotterell, T. Chakraborty, & Y. Zhou (Eds.), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2289–2303). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.naacl-main.182
Vidgen, B., Thrush, T., Waseem, Z., & Kiela, D. (2021). Learning from the worst: Dynamically generated datasets to improve online hate detection. In C. Zong, F. Xia, W. Li, & R. Navigli (Eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vol. 1, pp. 1667–1682). Association for Computational Linguistics. https://doi.org/10.18653/v1/2021.acl-long.132
Wang, K., Lu, D., Han, C., Long, S., & Poon, J. (2020). Detect all abuse! Toward universal abusive language detection models. In D. Scott, N. Bel, & C. Zong (Eds.), Proceedings of the 28th International Conference on Computational Linguistics (pp. 6366–6376). International Committee on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.560
Waseem, Z., Davidson, T., Warmsley, D., & Weber, I. (2017). Understanding abuse: A typology of abusive language detection subtasks. In Z. Waseem, W. H. K. Chung, D. Hovy, & J. Tetreault (Eds.), Proceedings of the First Workshop on Abusive Language Online (pp. 78–84). Association for Computational Linguistics. https://doi.org/10.18653/v1/W17-3012
Wiegand, M., Ruppenhofer, J., & Kleinbauer, T. (2019). Detection of abusive language: The problem of biased datasets. In J. Burstein, C. Doran, & T. Solorio (Eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol 1, pp. 602–608). Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1060
Zampieri, M., Malmasi, S., Nakov, P., Rosenthal, S., Farra, N., & Kumar, R. (2019). Predicting the type and target of offensive posts in social media. In J. Burstein, C. Doran, & T. Solorio (Eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol 1, pp. 1415–1420). Association for Computational Linguistics. https://doi.org/10.18653/v1/N19-1144
Zhang, W., Guo, H., Kivlichan, I. D., Prabhakaran, V., Yadav, D., & Yadav, A. (2023). A taxonomy of rater disagreements: Surveying challenges & opportunities from the perspective of annotating online toxicity. arXiv. https://doi.org/10.48550/arXiv.2311.04345
Ziems, C., Vigfusson, Y., & Morstatter, F. (2020). Aggressive, repetitive, intentional, visible, and imbalanced: Refining representations for cyberbullying classification. Proceedings of the International AAAI Conference on Web and Social Media, 14(1), 808–819. https://doi.org/10.1609/icwsm.v14i1.7345
Funding
This work was partially supported by NSF award #2318460.
Competing Interests
The authors declare no competing interests.
Ethics
This study does not involve human or animal subjects.
Copyright
This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided that the original author and source are properly credited.
Data Availability
All materials needed to replicate this study are available via the Harvard Dataverse: https://doi.org/10.7910/DVN/PQ1EH3
Authorship
Sai Koneru and Pranav Narayanan Venkit contributed equally to this work.