Peer Reviewed
Research note: Examining potential bias in large-scale censored data
Article Metrics
17
CrossRef Citations
PDF Downloads
Page Views
We examine potential bias in Facebook’s 10-trillion cell URLs dataset, consisting of URLs shared on its platform and their engagement metrics. Despite the unprecedented size of the dataset, it was altered to protect user privacy in two ways: 1) by adding differentially private noise to engagement counts, and 2) by censoring the data with a 100-public-share threshold for a URL’s inclusion. To understand how these alterations affect conclusions drawn from the data, we estimate the prevalence of fake news in the massive, censored URLs dataset and compare it to an estimate from a smaller, representative dataset. We show that censoring can substantially alter conclusions that are drawn from the Facebook dataset. Because of this 100-public-share threshold, descriptive statistics from the Facebook URLs dataset overestimate the share of fake news and news overall by as much as 4X. We conclude with more general implications for censoring data.
Editorial Staff Note
An Addendum to this article was published on February 24th, 2022.

Research Questions
- How do estimates of the prevalence of “fake news” on Facebook differ when measured in a large, censored dataset compared to a smaller, representative one?
- In general, how does censorship of large-scale data bias the key conclusions drawn from the data?
Essay Summary
- We estimate the percentage of clicks on Facebook in the U.S. that are not-fake news, fake news, and not-news using the Facebook URLs dataset, which censors URLs with fewer than 100 public shares. We then compare these results to those from an uncensored, representative dataset from Nielsen’s desktop web panel. We find that Facebook’s URLs dataset overestimates the relative share of news clicked on the platform by nearly 2X and fake news on the platform by 4X.
- Further matching between Facebook and Nielsen’s data, a CrowdTangle investigation, and an internal Facebook investigation show this overestimation is likely due to the 100-public-share threshold.
- This work demonstrates how “big data” can still lead to biased estimates if it is censored. In particular, this note shows that researchers working with the Facebook URLs dataset should be aware that the 100-public-share threshold can dramatically affect even basic descriptive statistics.
Implications
Private companies increasingly control vertically integrated platforms, which include both the production and consumption of information within their walled garden. Their data are critical to understanding news, advertisement, and purchase behavior; thus, academic researchers and data journalists are eager for these companies to release data. Social Science One has piloted a new program that provides approved researchers access to such datasets (King & Persily, 2018). Their first dataset includes all URLs on Facebook from January 2017 to July 2019 that were shared with the “public” setting by 100 or more users as well as accompanying interaction metrics like clicks, views, and shares. This article explores the value of that data: how effective it is for key social science questions, and what we learn about the impact of its privacy measures.
For privacy and business reasons this data is altered from the full scope of URLs shared on Facebook in two respects: first, by applying methods from differential privacy to the URL engagement counts; and second, by censoring the data to include only URLs that have been publicly shared at least 100 times. Much has been made of the first of these precautions (Evans & King, 2020; Gibney, 2019; Mervis, 2019; Messing et al., 2020), which was one of the first empirical applications of what was previously largely a theoretical idea (Dwork, 2008). In short, Facebook added noise to key values in order to ensure that while aggregated statistics are correct, it is impossible to identify individual user-level behavior from the data. However, the second precaution, censoring URLs below the 100-public-share threshold, has drawn less attention.
We find that censoring can substantially alter conclusions that are drawn from that data. First, we show that the percent of news and fake news on Facebook, key findings of interest to social scientists (for example, Guess et al., 2021), are both inflated compared to estimates from a representative dataset. We then provide evidence that this distortion likely comes from censoring. We take a random selection of URLs from the representative dataset and show that fake news URLs are much more likely to exist in the censored Facebook dataset than other URLs. Data from CrowdTangle confirm that fake news is more likely to be shared publicly than other types of URL content, perhaps due to its novelty or the distribution strategies of fake news producers. An internal investigation by Facebook supports our finding, showing that false news URLs are more likely to be shared publicly compared to other types of URLs, potentially introducing bias in the dataset (see Appendix 1).
This bias in the dataset is not limited to just news domains. An analysis of domains across a variety of other categories also found that while news and entertainment domains were more likely to be overrepresented in the Facebook URLs dataset, other types of URLs—e.g., retail, social-media, and gaming—were likely to be underrepresented (see Appendix 2). These biases offer insight into the relationships between viewing, clicking, and sharing (either publicly or privately) URLs on Facebook and how those relationships might differ depending on content type. Content that is likely to be shared conditional on being viewed or clicked, and conditional on being shared, be shared publicly, is overrepresented in the Facebook URLs dataset. Some content, like fake news, is optimized both to be clicked, since it is likely to be novel and have click-bait headlines, and to be shared publicly, since it is likely meant to draw others to engage. On the other hand, retail ads are optimized to be clicked due to personalized targeting, but not to be shared publicly, since they might contain private information that users would not want to disseminate. For example, micro-targeted Facebook ads containing links to political fundraising would likely be underrepresented in the Facebook URLs dataset, despite being of interest to researchers, because those types of URLs are unlikely to be shared publicly. Beyond just the questions of censorship in the Facebook URLs dataset, this research opens up many more questions into the relationships between viewing, clicking, and sharing URLs that are important avenues for future research.
We offer some potential suggestions to address the pitfalls of these biases. A better approach would be to eliminate censoring and rely entirely on differential privacy methods to avoid reidentification of individuals in the dataset. If the mere inclusion of a URL might violate privacy, e.g., if it is a link to a private photo album, another approach would be to provide the domain name but censor the full path of URLs below a certain threshold. This workaround would prevent the size of the dataset from exploding, while still allowing for detailed analysis at the domain level. Lowering the threshold may not be as effective of a strategy, since the CrowdTangle data suggested a big jump in fake news as a share of content from 0 to 1 (although the internal Facebook evaluation with false news URLs showed a jump closer to 25). Thus, while we appreciate that any lower threshold reduces bias, it is possible that bias would not be significantly reduced until the threshold was removed entirely.
When using the Facebook URLs dataset, researchers should provide compelling evidence that they are not comparing consumption across URL types that are likely to have different rates of public sharing. For example, comparing rates of fake news consumption across countries is likely to be biased, since fake news URLs in larger countries like India are much more likely to reach the 100-share threshold for inclusion than fake news URLs in smaller countries. Additionally, content that is mostly distributed through ads—like retail content, political donations, or inorganically-distributed disinformation—is not well-represented in the Facebook URLs dataset due to low likelihood of public sharing. On the other hand, organically shared hyperpartisan and fake news in the U.S. is likely to be captured in the Facebook URLs dataset and can be examined in isolation.
Despite the limitations we identify, the URLs dataset produced by the Facebook and Social Science One teams is unique in its size and richness. This article is not a critique of the larger effort, but rather is intended to probe the limits of the current methodology and raise awareness of potential bias to practitioners handling not only the Facebook dataset, but any large dataset with similar censorship issues.
Findings
Finding 1: Facebook URL dataset analysis
We matched our set of not-fake (i.e., credible) news and fake news domains to the Facebook URLs dataset and aggregated the number of clicks by U.S. users to not-fake news, fake news, and not-news domains. From 1/2017–12/2018, an average of 12% of clicks per month went to fake news content, 32% went to not-fake news content, and 56% went to other, not-news content. The results are shown in Figure 1. The estimates for both non-fake news and fake news are much higher than other prevailing estimates (Allen et al., 2020; Grinberg et al., 2019; Guess et al., 2019).
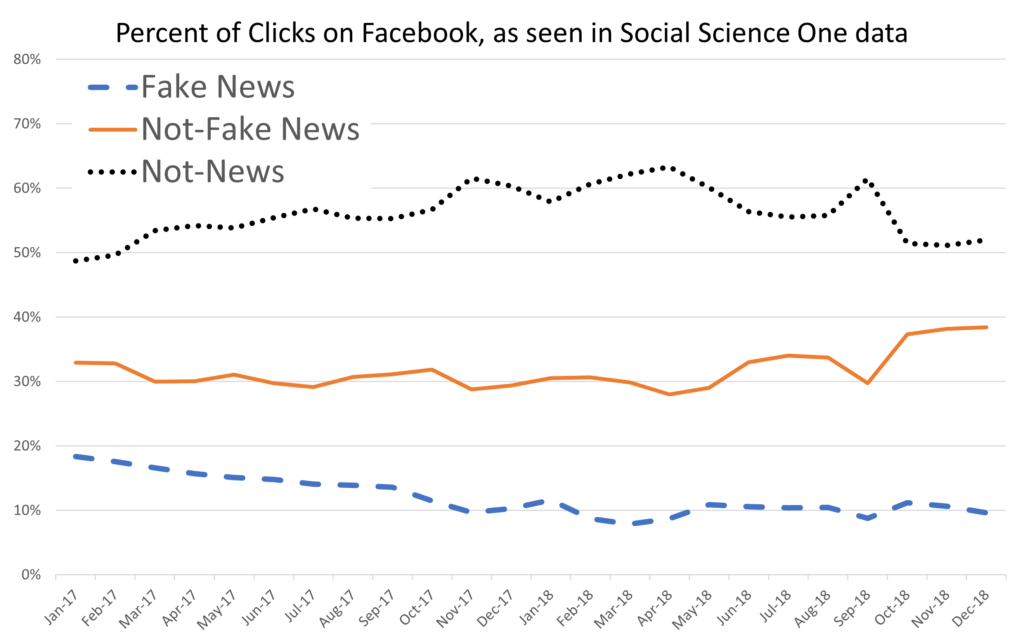
To investigate this discrepancy, we picked the month of December 2018 to do cross-dataset analysis with the Nielsen dataset (we chose this month because it was the last month for which we had access to both datasets, although our high-level findings are robust to the month picked). In that month of the Facebook dataset, we found that 10% of clicks went to fake news, 38% of clicks went to not-fake news, and 52% of clicks went to not-news sites (shown in Column B in Table 1). We then took a random sample of 1,000 URLs from Nielsen visited by our panelists, clicked from Facebook newsfeed, during the same month. Unlike the Facebook dataset, we observed all the URLs that people visit rather than a censored version of URLs with greater than 100 public shares. We then processed those URLs in the same format as the Facebook dataset and categorized them using the same domain lists that we used for the Facebook URLs. Following this procedure, we found that 2.5% of clicks were to fake news, 24% of clicks were to not-fake news, and 74% of clicks were to not-news sites (shown in Column A in Table 1). These results are starkly different from those estimates found using the Facebook URLs data. In particular, the Facebook URLs data seem to be overcounting news: an almost 4X difference in the amount of fake news and 1.7X difference in the amount of not-fake news.
We hypothesized that this difference in estimates was due to the 100-public-share threshold for inclusion in the Facebook URLs dataset. To test our hypothesis systematically, we attempted to find matches for all the URLs in our Nielsen dataset in the Facebook URLs dataset, with the assumption that those URLs with matches had met the 100-public-share threshold and those without matches did not. We found that 84% of fake news URLs in our Nielsen sample were also present in the Facebook dataset, but only 50% of not-fake news URLs and 23% of not-news URLs were. Fake news was thus 4X more likely to be found in the Facebook dataset than not-news URLs, and 1.7X more likely than not-fake news. When we recalculated the proportion of fake news, not-fake news, and not-news using this matched dataset—dropping the Nielsen URLs without Facebook matches—we found that 7% were fake news, 39% were not-fake news, and 55% were not-news. These estimates, in Column C of Table 1, are much closer to those of the Facebook URLs dataset shown in Column B of Table 1, providing support for our hypothesis that the 100-public-share threshold adds bias to the estimates.
Finding 2: CrowdTangle analysis
To further examine whether these differences in match rates were the result of differential public sharing rates vs. other behaviors, we used the CrowdTangle API to query the number of CrowdTangle public shares for each URL in our dataset since January 2017. Unfortunately, CrowdTangle has a more restrictive definition for public shares than Facebook does. CrowdTangle share counts are limited to only those articles shared by public pages, groups, or users with “public” profiles, who usually are public figures like politicians or celebrities. However, we can still use this data as a benchmark, since the number of CrowdTangle public shares is a lower bound for the number of total public shares.
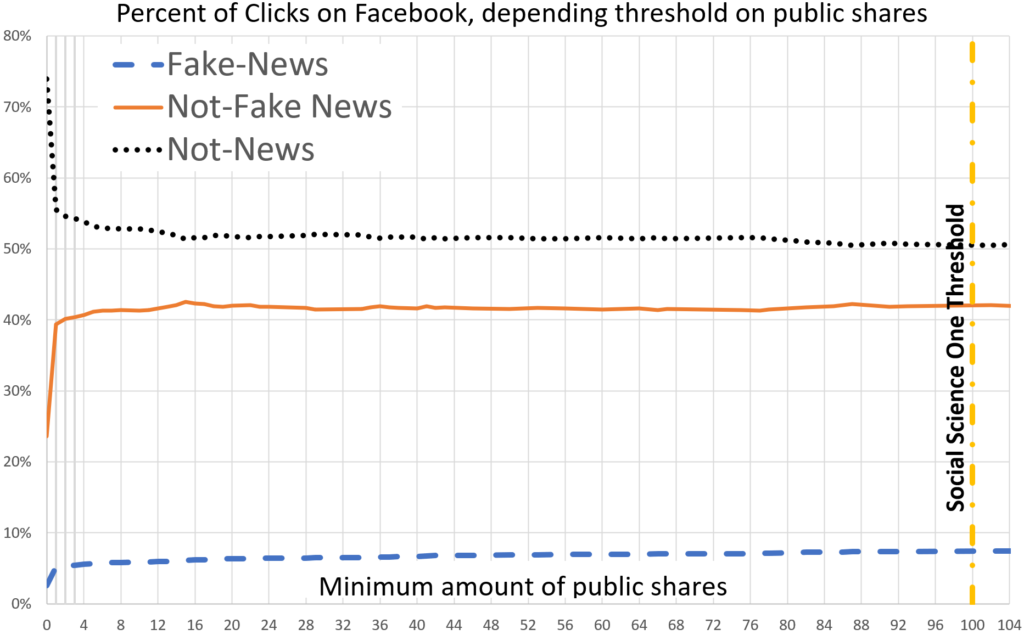
The results from this analysis are shown in Figure 2 and summarized in Table 1, Column D. In short, despite the difference in the definition of public shares, we find results that are very similar to those presented using the Facebook dataset. Above the 100 CrowdTangle share threshold, 7% of clicks were to fake news sites, 42% of clicks were to not-fake news sites, and 51% of clicks were to non-news sites. As Figure 2 shows, this difference in results was driven by a large spike in not-news URLs with 0 CrowdTangle shares. These include the long tail of ad clicks, personal links, and approximately 30% of not-fake news URLs.While most of the change occurred from 0 to 1 share, the percent of all URL content that was fake news also increased from 5.1% to 7.4% –a 45% increase–as the threshold changed from 1 CrowdTangle share to 100. Similarly, the percent of news that was fake went from 11.5% to 15%, a 36% increase. These results show that fake news URLs have a disproportionately high percentage of public shares from pages or verified profiles, which supports the anecdotal evidence suggesting that fake news peddlers use public pages as a distribution channel (Legum, 2019; Roose, 2020).
| (a) Nielsen: from Facebook | (b) Facebook URLs dataset | (c) Nielsen: in Facebook URLs Dataset | (d) Nielsen: >100 CrowdTangle Public Shares | |
| Fake-News | 2.5% | 10% | 7% | 7% |
| Not-Fake News | 24% | 38% | 39% | 42% |
| Not-News | 74% | 52% | 55% | 51% |
Methods
To define not-fake news and fake news, we used the same domains as in Allen et al. (2020). The list of not-fake news sites was composed of more than 9,000 websites that primarily covered “hard” news topics like politics, business, and U.S. and international affairs. The list of fake news sites was composed of the 624 websites previously identified by researchers, professional fact checkers, and journalists as sources of fake, deceptive, low-quality, or hyperpartisan news. All other domains were classified as not-news domains.
Facebook Social Science One Dataset: In 2020, Facebook released a massive dataset of URLs (Messing et al., 2020). The first component was 38 million+ URLs that were shared from 1/1/2017 to 7/31/2019, as well as various descriptive characteristics like third-party fact-checker ratings. The second component contained over 10 trillion cells with aggregate consumption data like views and clicks for each URL for different combinations of demographic data. Facebook de-duplicated each action such that the engagement metrics reported are not the total number of clicks (or shares, etc.), but rather the total number of users who clicked (or shared) the URL. For example, a given row might describe the number of times a particular URL was clicked, shared, and viewed by women in the U.S., aged 18–24, who lean conservative, in January 2018.
Facebook also added differentially private noise to the engagement-related columns of the dataset. While this noise can change the results of many statistical procedures, the sums of differentially private columns are unbiased estimates of the true sums and thus, we did not do any further corrections in our analysis.
Additionally, Facebook restricted URLs in this dataset to those that have been shared publicly by 100 different users (plus Laplace[5] noise to minimize information leakage). Facebook defines a public share as a user or page post of any link with the privacy set to “Public” as opposed to “Friends,” “Only Me,” or a custom audience. While Facebook offers documentation about their privacy options, they do not provide statistics about how much content on the site is shared with the “public” setting. However, the default for posting is “Public” until the user changes their settings.
Facebook implemented this 100-public-share threshold in an attempt to further ensure the privacy of users. Many links were created by users to share private material with a small group of friends and not to broadcast information publicly (e.g., a photo album or a personal PayPal link). This could include private links, but also technically public links, which maintain privacy through low engagement (i.e., security through obscurity). Thus, a 100-public-share threshold was a heuristic to ensure that these personal links were not exposed to researchers since these kinds of links were likely to be posted with more restricted sharing settings by a limited number of people.
As a comparison, we used data from a nationally representative desktop web panel from the company Nielsen from 2016 to present. The data included every URL that each individual panelist visited as well as the time of visit. We used this data to identify URLs that panelists clicked on while on Facebook’s newsfeed by examining URLs that included the “fbclid” parameter. In late 2018, Facebook added this parameter to URLs shared on the platform, such that when a user clicks a URL from Facebook (but not Facebook Messenger), the URL they navigate to takes the form “www.domain.com?fbclid=XXXX”.
Unlike the Facebook URLs data, the Nielsen data had neither noise nor censorship and had data from a demographically representative random subset of users. There were several more key differences. First, the Facebook URLs dataset did not include clicks from Facebook Messenger, while the Nielsen data captured all activity from Facebook including Facebook Messenger. However, by using the “fbclid” parameter, which does not appear in URLs shared in private messages, we were able to exclude Nielsen referrals that might have come from Facebook Messenger. Additionally, one might be concerned that URLs with the “fbclid” parameter could have originated from sources other than Facebook, such as by users copy-and-pasting URLs from Facebook and sending them via email, but an analysis suggests that this concern is likely unfounded and further restricting the definition of Facebook referrals does not alter results (see Appendix 3). Second, the Nielsen data was not de-duplicated (although results are robust to de-duplicating the Nielsen data, see Appendix 3). Third, Nielsen was desktop only, while the Facebook URLs dataset included mobile.
As part of Social Science One, we gained access to the CrowdTangle API. CrowdTangle, which is owned by Facebook, tracks engagement on public content on Facebook and makes it available to journalists and researchers. Unlike the Facebook URLs dataset, this data is not de-duplicated at the user level. In particular, the API allows researchers to identify the number of shares from public pages, groups, or profiles for a given URL on the Facebook platform.
Bibliography
Allen, J., Howland, B., Mobius, M., Rothschild, D., & Watts, D. J. (2020). Evaluating the fake news problem at the scale of the information ecosystem. Science Advances, 6(14), eaay3539. https://doi.org/10.1126/sciadv.aay3539
Dwork C. (2008). Differential privacy: A survey of results. In Agrawal M., Du D., Duan Z., & Li A. (Eds.), Theory and applications of models of computation (TAMC 2008) (pp. 1–19). Springer. https://doi.org/10.1007/978-3-540-79228-4_1
Evans, G. & King, G. (2020). Statistically valid inferences from differentially private data releases, with application to the Facebook URLs dataset [Manuscript submitted for publication]. Harvard University. https://gking.harvard.edu/dpd
Gibney, E. (2019). Privacy hurdles thwart Facebook democracy research. Nature, 574(7777), 158–159. https://doi.org/10.1038/d41586-019-02966-x
Grinberg, N., Joseph, K., Friedland, L., Swire-Thompson, B., & Lazer, D. (2019). Fake news on Twitter during the 2016 U.S. presidential election. Science, 363(6425), 374–378. https://doi.org/10.1126/science.aau2706
Guess, A., Aslett, K., Tucker, J., Bonneau, R., & Nagler, J. (2021). Cracking open the news feed: Exploring what US Facebook users see and share with large-scale platform data. Journal of Quantitative Description: Digital Media, 1, 1–48. https://doi.org/10.51685/jqd.2021.006
Guess, A., Nagler, J., & Tucker, J. (2019). Less than you think: Prevalence and predictors of fake news dissemination on Facebook. Science Advances, 5(1), eaau4586. https://doi.org/10.1126/sciadv.aau4586
King, G., & Persily, N. (2020). A new model for industry–academic partnerships. PS: Political Science & Politics, 53(4), 703–709. https://doi.org/10.1017/S1049096519001021
Legum, J. (2019, October 28). Facebook allows prominent right-wing website to break the rules. Popular Information Newsletter. https://popular.info/p/facebook-allows-prominent-right-wing
Mervis, J. (2019). Privacy concerns could derail Facebook data-sharing plan. Science, 365(6460), 1360–1361. https://doi.org/10.1126/science.365.6460.1360
Messing, S., DeGregorio, C., Hillenbrand, B., King, G., Mahanti, S., Nayak, C., Persily, N., State, Bogdan, & Wilkins, A. (2020). Facebook privacy-protected full URLs data set [Data set]. https://doi.org/10.7910/DVN/TDOAPG
Matsakis, L. (2019, January 23). Facebook cracks down on networks of fake pages and groups. Wired. https://www.wired.com/story/facebook-pages-misinformation-networks/
Roose, K. (2020, August 27). What if Facebook is the real “silent majority”? The New York Times. https://www.nytimes.com/2020/08/27/technology/what-if-facebook-is-the-real-silent-majority.html
Funding
We are grateful to Nielsen for access to panel data. Additional financial support for this research was provided by the Nathan Cummings Foundation (grants 17-07331 and 18-08129) and the Andrew Carnegie Corporation of New York (G-F-20-57741).
Competing Interests
Facebook researchers performed the analysis in Appendix Section 1. J.A. has a significant financial interest in Facebook.
Ethics
No data were collected from human subjects specifically for this project.
Copyright
This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided that the original author and source are properly credited.
Data Availability
All materials needed to replicate this study are available via the Harvard Dataverse: https://doi.org/10.7910/DVN/L0ZXYE